Crossposted from AI Impacts blog
The 2023 Expert Survey on Progress in AI is out, this time with 2778 participants from six top AI venues (up from about 700 and two in the 2022 ESPAI), making it probably the biggest ever survey of AI researchers.
People answered in October, an eventful fourteen months after the 2022 survey, which had mostly identical questions for comparison.
Here is the preprint. And here are six interesting bits in pictures (with figure numbers matching paper, for ease of learning more):
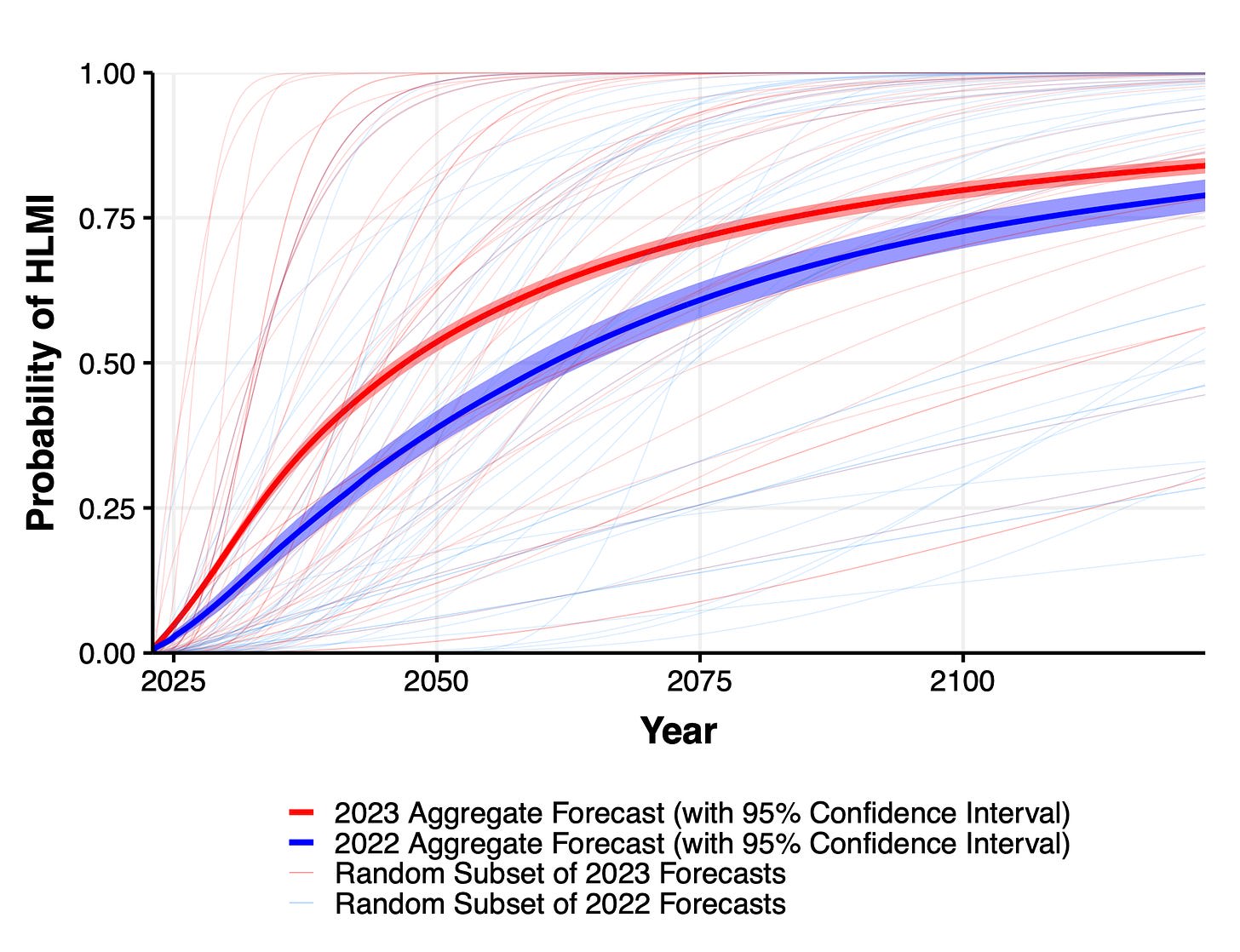
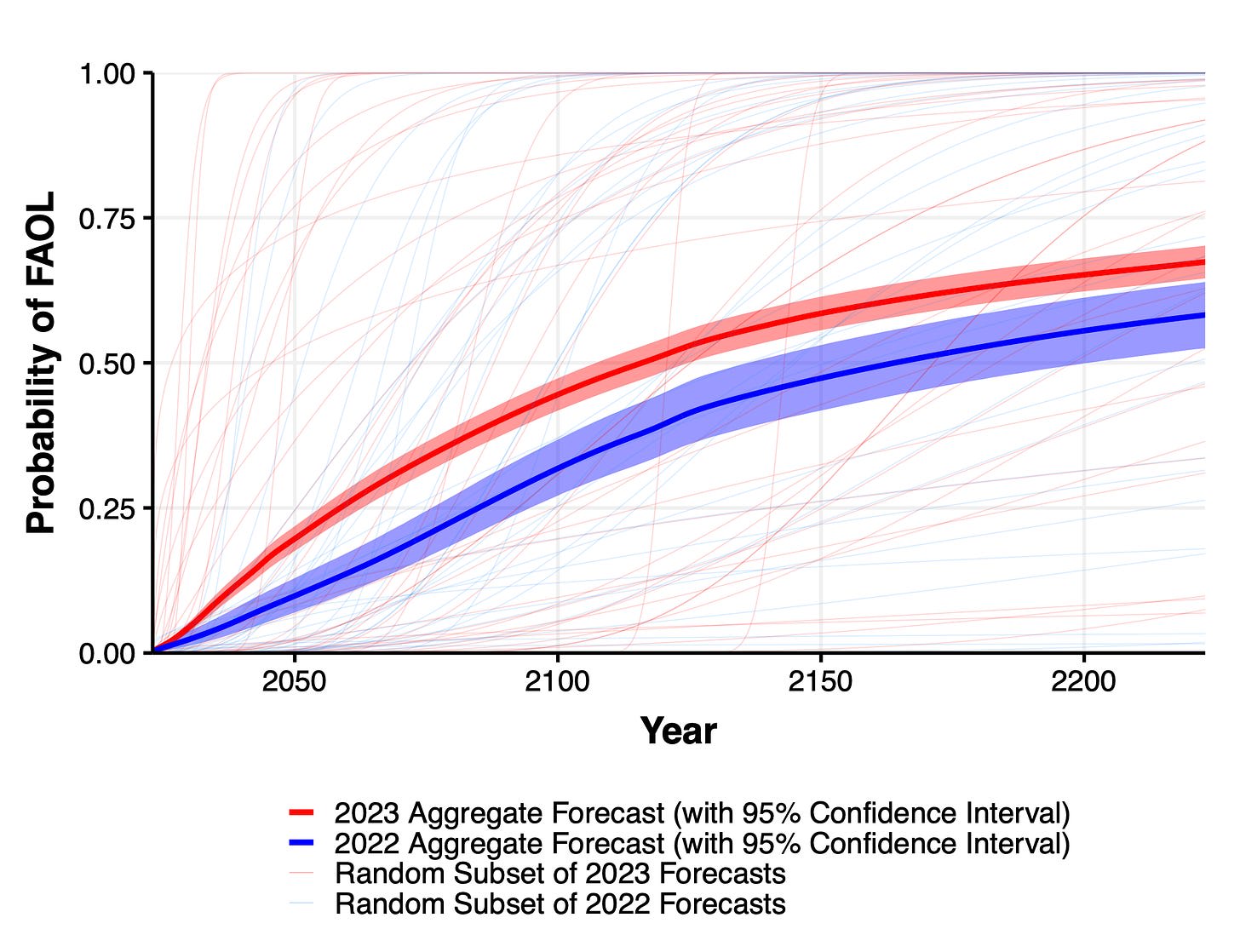
1. Expected time to human-level performance dropped 1-5 decades since the 2022 survey. As always, our questions about ‘high level machine intelligence’ (HLMI) and ‘full automation of labor’ (FAOL) got very different answers, and individuals disagreed a lot (shown as thin lines below), but the aggregate forecasts for both sets of questions dropped sharply. For context, between 2016 and 2022 surveys, the forecast for HLMI had only shifted about a year.
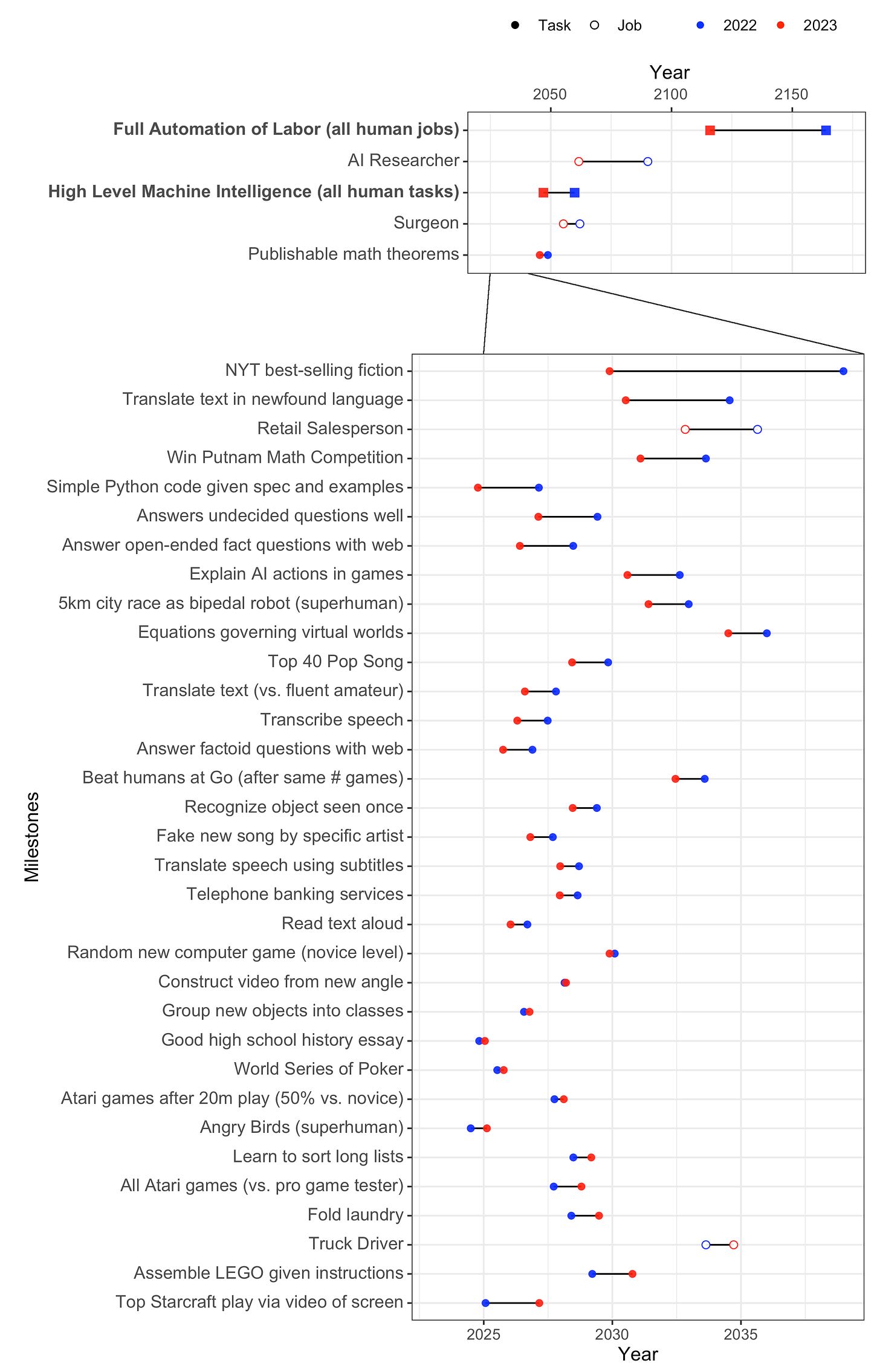
2. Time to most narrow milestones decreased, some by a lot. AI researchers are expected to be professionally fully automatable a quarter of a century earlier than in 2022, and NYT bestselling fiction dropped by more than half to ~2030. Within five years, AI systems are forecast to be feasible that can fully make a payment processing site from scratch, or entirely generate a new song that sounds like it’s by e.g. Taylor Swift, or autonomously download and fine-tune a large language model.
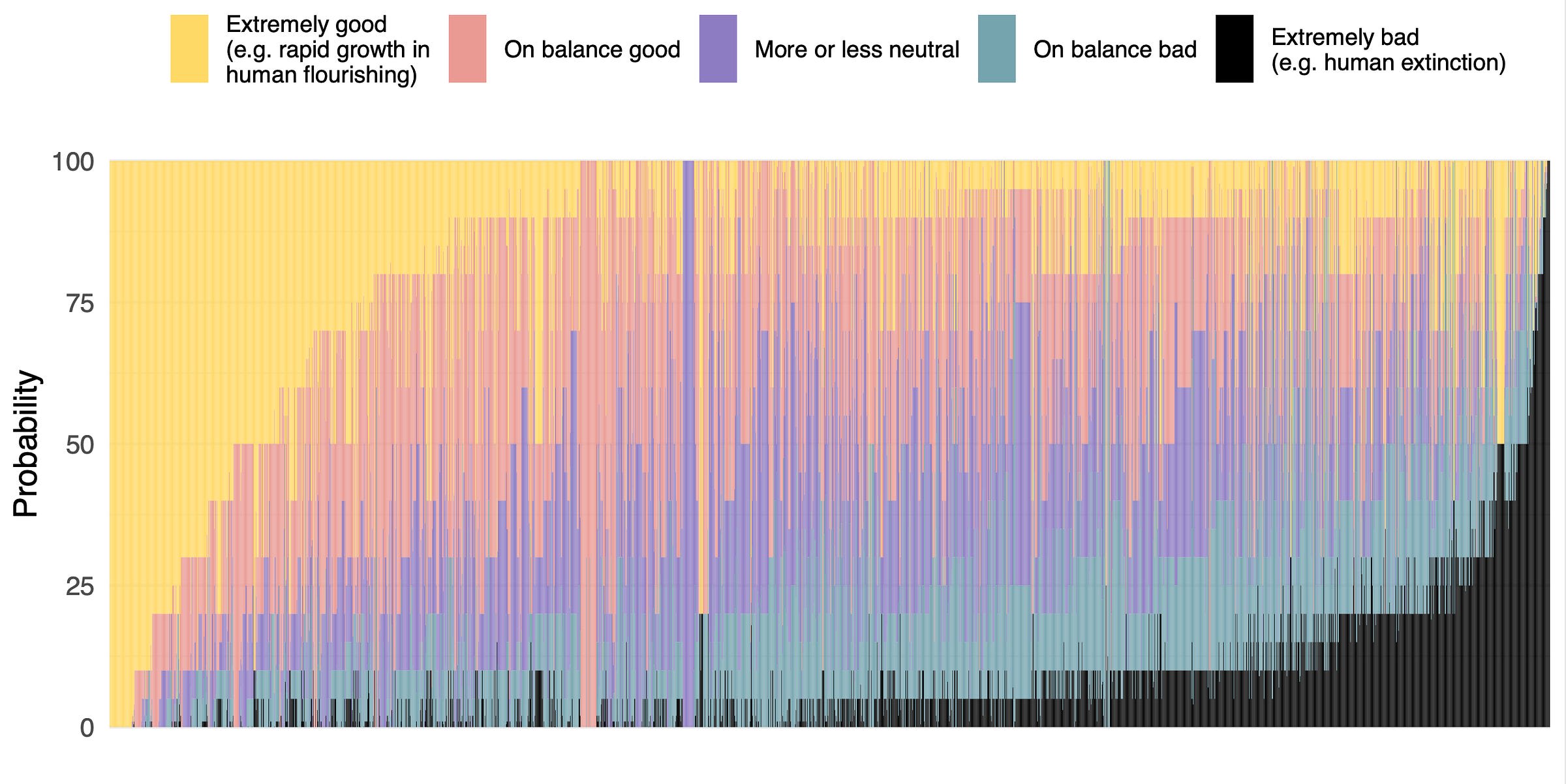
3. Median respondents put 5% or more on advanced AI leading to human extinction or similar, and a third to a half of participants gave 10% or more. This was across four questions, one about overall value of the future and three more directly about extinction.

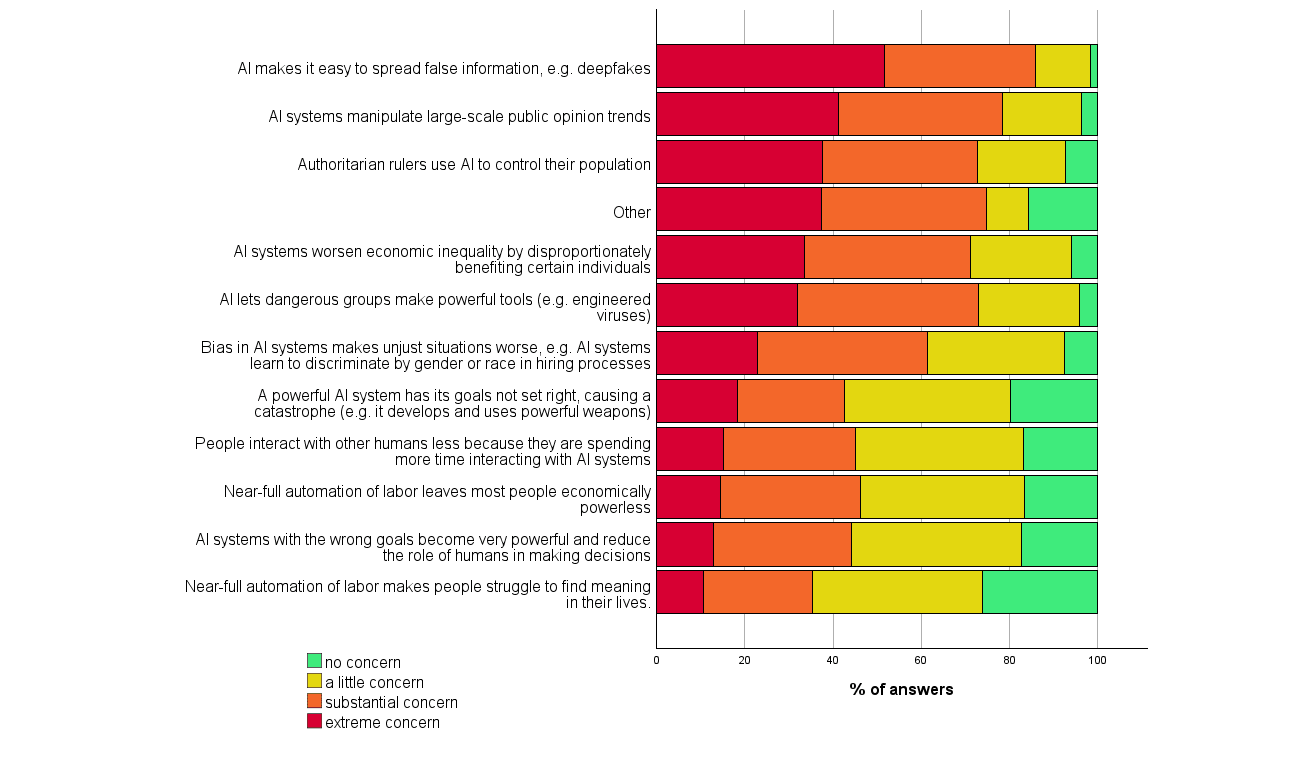
4. Many participants found many scenarios worthy of substantial concern over the next 30 years. For every one of eleven scenarios and ‘other’ that we asked about, at least a third of participants considered it deserving of substantial or extreme concern.
5. There are few confident optimists or pessimists about advanced AI: high hopes and dire concerns are usually found together. 68% of participants who thought HLMI was more likely to lead to good outcomes than bad, but nearly half of these people put at least 5% on extremely bad outcomes such as human extinction, and 59% of net pessimists gave 5% or more to extremely good outcomes.
6. 70% of participants would like to see research aimed at minimizing risks of AI systems be prioritized more highly. This is much like 2022, and in both years a third of participants asked for “much more”—more than doubling since 2016.

If you enjoyed this, the paper covers many other questions, as well as more details on the above. What makes AI progress go? Has it sped up? Would it be better if it were slower or faster? What will AI systems be like in 2043? Will we be able to know the reasons for its choices before then? Do people from academia and industry have different views? Are concerns about AI due to misunderstandings of AI research? Do people who completed undergraduate study in Asia put higher chances on extinction from AI than those who studied in America? Is the ‘alignment problem’ worth working on?
I appreciate that a ton of work went into this, and the results are interesting. That said, I am skeptical of the value of surveys with low response rates (in this case, 15%), especially when those surveys are likely subject to non-response bias, as I suspect this one is, given: (1) many AI researchers just don’t seem too concerned about the risks posed by AI, so may not have opened the survey and (2) those researchers would likely have answered the questions on the survey differently. (I do appreciate that the authors took steps to mitigate the risk of non-response bias at the survey level, and did not find evidence of this at the question level.)
I don’t find the “expert surveys tend to have low response rates” defense particularly compelling, given: (1) the loaded nature of the content of the survey (meaning bias is especially likely), (2) the fact that such a broad group of people were surveyed that it’s hard to imagine they’re all actually “experts” (let alone have relevant expertise), (3) the fact that expert surveys often do have higher response rates (26% is a lot higher than 15%), especially when you account for the fact that it’s extremely unlikely other large surveys are compensating participants anywhere close to this well, and (4) the possibility that many expert surveys just aren’t very useful.
Given the non-response bias issue, I am not inclined to update very much on what AI researchers in general think about AI risk on the basis of this survey. I recognize that the survey may have value independent of its knowledge value—for instance, I can see how other researchers citing these kinds of results (as I have!) may serve a useful rhetorical function, given readers of work that cites this work are unlikely to review the references closely. That said, I don’t think we should make a habit of citing work that has methodological issues simply because such results may be compelling to people who won’t dig into them.
Given my aforementioned concerns, I wonder whether the cost of this survey can be justified (am I calculating correctly that $138,000 was spent just compensating participants for taking this survey, and that doesn’t include other costs, like those associated with using the outside firm to compensate participants, researchers’ time, etc?). In light of my concerns about cost and non-response bias, I am wondering whether a better approach would instead be to randomly sample a subset of potential respondents (say, 4,000 people), and offer to compensate them at a much higher rate (e.g., $100), given this strategy could both reduce costs and improve response rates.
Quantitatively how large do you think the non-response bias might be? Do you have some experience or evidence in this area that would help estimate the effect size? I don't have much to go on, so I'd definitely welcome pointers.
Let's consider the 40% of people who put a 10% probability on extinction or similarly bad outcomes (which seems like what you are focusing on). Perhaps you are worried about something like: researchers concerned about risk might be 3x more likely to answer the survey than those who aren't concerned about risk, and so in fact only 20% of people assign a 10% probability, not the 40% suggested by the survey.
Changing from 40% to 20% would be a significant revision of the results, but honestly that's probably comparable to other sources of error and I'm not sure you should be trying to make that precise an inference.
But more importantly a 3x selection effect seems implausibly large to me. The survey was presented as being about "progress in AI" and there's not an obvious mechanism for huge selection effects on these questions. I haven't seen literature that would help estimate the effect size, but based on a general sense of correlation sizes in other domains I'd be pretty surprised by getting a 3x or even 2x selection effect based on this kind of indirect association. (A 2x effect on response rate based on views about risks seems to imply a very serious piranha problem)
The largest demographic selection effects were that some groups (e.g. academia vs industry, junior vs senior authors) were about 1.5x more likely to fill out the survey. Those small selection effects seem more like what I'd expect and are around where I'd set the prior (so: 40% being concerned might really be 30% or 50%).
I think the survey was described as about "progress in AI" (and mostly concerned progress in AI), and this seems like all people saw when deciding to take it. Once people started taking the survey it looks like there was negligible non-response at the question level. You can see the first page of the survey here, which I assume is representative of what people saw when deciding to take the survey.
I'm not sure if this was just a misunderstanding of the way the survey was framed. Or perhaps you think people have seen reporting on the survey in previous years and are aware that the question on risks attracted a lot of public attention, and therefore are much more likely to fill out the survey if they think risk is large? (But I think the mechanism and sign here are kind of unclear.)
If compensation is a significant part of why participants take the survey, then I think it lowers the scope for selection bias based on views (though increases the chances that e.g. academics or junior employees are more likely to respond).
I think it's dishonest to cite work that you think doesn't provide evidence. That's even more true if you think readers won't review the citations for themselves. In my view the 15% response rate doesn't undermine the bottom line conclusions very seriously, but if your views about non-response mean the survey isn't evidence then I think you definitely shouldn't cite it.
I think the goal was to survey researchers in machine learning, and so it was sent to researchers who publish in the top venues in machine learning. I don't think "expert" was meant to imply that these respondents had e.g. some kind of particular expertise about risk. In fact the preprint emphasizes that very few of the respondents have thought at length about the long-term impacts of AI.
I think it can easily be justified. This survey covers a set of extremely important questions, where policy decisions have trillions of dollars of value at stake and the views of the community of experts are frequently cited in policy discussions.
You didn't make your concerns about selection bias quantitative, but I'm skeptical about quantitatively how much they decrease the value of information. And even if we think non-response is fatal for some purposes, it doesn't interfere as much with comparisons across questions (e.g. what tasks do people expect to be accomplished sooner or later, what risks do they take more or less seriously) or for observing how the views of the community change with time.
I think there are many ways in which the survey could be improved, and it would be worth spending additional labor to make those improvements. I agree that sending a survey to a smaller group of recipients with larger compensation could be a good way to measure the effects of non-response bias (and might be more respectful of the research community's time).
I think the main takeaway w.r.t. risk is that typical researchers in ML (like most of the public) have not thought about impacts of AI very seriously but their intuitive reaction is that a range of negative outcomes are plausible. They are particularly concerned about some impacts (like misinformation), particularly unconcerned about others (like loss of meaning), and are more ambivalent about others (like loss of control).
I think this kind of "haven't thought about it" is a much larger complication for interpreting the results of the survey, although I think it's fine as long as you bear it in mind. (I think ML researchers who have thought about the issue in detail tend if anything to be somewhat more concerned than the survey respondents.)
My impressions of academic opinion have been broadly consistent with these survey results. I agree there is large variation and that many AI researchers are extremely skeptical about risk.
I really appreciate your and @Katja_Grace's thoughtful responses, and wish more of this discussion had made it into the manuscript. (This is a minor thing, but I also didn't love that the response rate/related concerns were introduced on page 20 [right?], since it's standard practice—at least in my area—to include a response rate up front, if not in the abstract.) I wish I had more time to respond to the many reasonable points you've raised, and will try to come back to this in the next few days if I do have time, but I've written up a few thoughts here.
Note that we didn't tell them the topic that specifically.
Tried sending them $100 last year and if anything it lowered the response rate.
If you are inclined to dismiss this based on your premise "many AI researchers just don’t seem too concerned about the risks posed by AI", I'm curious where you get that view from, and why you think it is a less biased source.
I understand that, and think this was the right call. But there seems to be consensus that in general, a response rate below ~70% introduces concerns of non-response bias, and when you're at 15%—with (imo) good reason to think there would be non-response bias—you really cannot rule this out. (Even basic stuff like: responders probably earn less money than non-responders, and are thus probably younger, work in academia rather than industry, etc.; responders are more likely to be familiar with the prior AI Impacts survey, and all that that entails; and so on.) In short, there is a reason many medical journals have a policy of not publishing surveys with response rates below 60%; e.g., JAMA asks for >60%, less prestigious JAMA journals also ask for >60%, and BMJ asks for >65%. (I cite medical journals because their policies are the ones I'm most familiar with, not because I think there's something special about medical journals.)
I find it a bit hard to believe that this lowered response rates (was this statistically significant?), although I would buy that it didn't increase response rates much, since I think I remember reading that response rates fall off pretty quickly as compensation for survey respondents increases. I also appreciate that you're studying a high-earning group of experts, making it difficult to incentivize participation. That said, my reaction to this is: determine what the higher-order goals of this kind of project are, and adopt a methodology that aligns with that. I have a hard time believing that at this price point, conducting a survey with a 15% response rate is the optimal methodology.
My impression stems from conversations I've had with two CS professor friends about how concerned the CS community is about the risks posed by AI. For instance, last week, I was discussing the last AI Impacts survey with a CS professor (who has conducted surveys, as have I); I was defending the survey, and they were criticizing it for reasons similar to those outlined above. They said something to the effect of: the AI Impacts survey results do not align with my impression of people's level of concern based on discussions I've had with friends and colleagues in the field. And I took that seriously, because this friend is EA-adjacent; extremely competent, careful, and trustworthy; and themselves sympathetic to concerns about AI risk. (I recognize I'm not giving you enough information for this to be at all worth updating on for you, but I'm just trying to give some context for my own skepticism, since you asked.)
Lastly, as someone immersed in the EA community myself, I think my bias is—if anything—in the direction of wanting to believe these results, but I just don't think I should update much based on a survey with such a low response rate.
I think this is going to be my last word on the issue, since I suspect we'd need to delve more deeply into the literature on non-response bias/response rates to progress this discussion, and I don't really have time to do that, but if you/others want to, I would definitely be eager to learn more.
Just to give your final point some context: the average in-depth research project by Rethink Priorities reportedly costs $70K-$100K. So, if this AI Impacts survey cost $138K in participant compensation, plus some additional amount for things like researcher time, then it looks like this survey was two or three times more expensive than the average research project in its approximate reference class.
I haven’t thought hard about whether the costs of EA-funded research make sense in general, but I thought I’d leave this comment so that readers don’t go away thinking that this survey cost like an order of magnitude more than what’s standard.
Note that 4,000 * $100 is $400,000 which is higher than the cost you cited above.
FWIW, both of these costs seem pretty small to me.
No, because the response rate wouldn't be 100%; even if it doubled to 30% (which I doubt it would), the cost would still be lower ($120k).
Link-commenting my Twitter thread of immediate reaction and summary of paper. Some light editing for readability. Would be interested on feedback if this slightly odd for a forum comment content is helpful or interesting to people.
Overall take: this is a well done survey, but all surveys of this sort have big caveats. I think this survey is as good as it is reasonable to expect a survey of AI researchers to be. But, there is still likely bias due to who chooses to respond, and it's unclear how much we should be deferring to this group. It would be good to see an attempt to correct for response bias (eg weighting). Appendix D implies it would likely only have small effects though, except widening the distributions because women were more uncertain and less likely to respond.
Timelines
Wording of questions matters a lot when asking about time for AI to be able to do all tasks/jobs. 60 year difference in median due to a small change, which researchers can't explain. Will allow cherry picking to support different arguments. In particular, Timeline predictions are extremely non-robust. HLMI = High-Level Machine Intelligence. FAOL = Full Automation of Labor. 60 year apart in time to occurence.
Other bits of question wording matter, not anywhere near as much (see below). Annoyingly, there's no CIs for the median times so it's hard to assess how much is noise. I guess not much due to the sample size.
This might be just uncertainty though. Any single year is a bad summary when uncertainty is this high. The ranges below are where the distribution aggregated across researchers place 50% of the mass.
I find it very amusing that AI researchers think the hardest task to get AI to do (of all the ones they asked about) is... Being an AI researcher. Glad they're confident in their own job security.
Note that time to being "feasible" is defined quite loosely. It would still cost millions of dollars (if not more) to implement and only be available to top labs. Annoyingly, it means that the predictions can only be falsified as too long, not too short.
The aggregation is making a strong assumption about the shape of respondents' distribution. I'm suspicious of any extrapolation or interpolation based on it. A sensitivity analysis would be nice here. Also, why not a three-parmeter distribution so it can be fit exactly?
Time to ~AGI in 2016 and 2022 surveys very similar, but big change in median times for 2023. Remember previous caveat about no CIs and wide distributions though.
Some recommendations on quoting timelines from this survey.
Outcomes of AGI
I don't have much to say on the probabilities of different oucomes. I note they're aggregating with means/medians. These reduce the weight on very low end or very high probabilities a lot (relative to geometric mean of odds, which I think is better). So these are probably closer to 50% than they should be.
Headline result below! Probability of very bad outcomes, conditional on high-level machine intelligence existing. Median respondent unchanged at 5-10%. I'd guess heavily affected by rounding and putting 5% for "small chance, don't know". An upper bound on the truth for AI researchers' median IMO.
There's lots of demographic breakdowns, mostly uninteresting IMO. They didn't ask or otherwise assess how much work respondents had done on AI safety. Would have been interesting to see the split and also to assess response bias.
Thanks for citing the survey here, and thank you Joshua for your analysis.
Your post doesn´t seem strange to me at this place; at the very least I can´t find any harm in posting it here. (If someone is more interested in other discussions, they may read the first two lines and then skip it.) The only question would be if this is worth YOUR time, and I am confident you are able to judge this (and you apparently did and found it worth your time).
Since you already delved that deep into the material and since I don´t see myself doing the same, here a question to you (or whoever else feeling inclined to answer):
Were there a significant part of experts who thought that HLMI and/or FAOL are downright impossible (at least with anything resembling our current approaches)? I do hear/read doubts like these sometimes. If so, how were these experts included in the mean, since you can´t just include infinity with non-zero probability without the whole number going up to infinity? (If they even used a mean. "Aggregate Forecast" is not very clear; if they used the median ore something similar the second question can be ignored.)