Summary
TLDR
Responsible Scaling Policies (RSPs) have been recently proposed as a way to keep scaling frontier large language models safely.
While being a nice attempt at committing to specific practices, the framework of RSP is:
- missing core components of basic risk management procedures (Section 2 & 3)
- selling a rosy and misleading picture of the risk landscape (Section 4)
- built in a way that allows overselling while underdelivering (Section 4)
Given that, I expect the RSP framework to be negative by default (Section 3, 4 and 5). Instead, I propose to build upon risk management as the core underlying framework to assess AI risks (Section 1 and 2). I suggest changes to the RSP framework that would make it more likely to be positive and allow to demonstrate what it claims to do (Section 5).
Section by Section Summary:
General Considerations on AI Risk Management
This section provides background on risk management and a motivation for its relevance in AI.
- Proving risks are below acceptable levels is the goal of risk management.
- To do that, acceptable levels of risks (not only of their sources!) have to be defined.
- Inability to show that risks are below acceptable levels is a failure. Hence, the less we understand a system, the harder it is to claim safety.
- Low-stake failures are symptoms that something is wrong. Their existence make high-stake failures more likely.
What Standard Risk Management Looks Like
This section describes the main steps of most risk management systems, explains how it applies to AI, and provides examples from other industries of what it looks like.
- Define Risk Levels: Set acceptable likelihood and severity.
- Identify Risks: List all potential threats.
- Assess Risks: Evaluate their likelihood and impact.
- Treat Risks: Adjust to bring risks within acceptable levels.
- Monitor: Continuously track risk levels.
- Report: Update stakeholders on risks they incur and measures taken.
RSPs vs Standard Risk Management
This section provides a table comparing RSPs and generic risk management standard ISO/IEC 31000, explaining the weaknesses of RSPs.
It then provides a list of 3 of the biggest failures of RSPs compared with risk management.
Prioritized RSPs failures against risk management:
- Using underspecified definitions of risk thresholds and not quantifying the risk.
- Claiming “responsible scaling” without including a process to make the assessment comprehensive.
- Including a white knight clause that kills commitments.
Why RSPs Are Misleading and Overselling
Misleading points:
- Anthropic RSP labels misalignment risks as “speculative” with minimal justification.
- The framing implies that not scaling for a long time is not an option.
- RSPs present an extremely misleading view of what we know of the risk landscape.
Overselling and Underdelivering
- RSPs allow for weak commitments within a large framework that could in theory be strong.
- No one has given evidence that substantial improvements to a framework have ever happened in the timelines we’re talking about (a few years), which is the whole pitch of RSPs.
- "Responsible scaling" is misleading; "catastrophic scaling" might be more apt if we can’t rule out 1% extinction risk (it is the case for ASL-3).
Are RSPs Hopeless?
This section explains why using RSPs as a framework is inadequate, even compared to just starting from already-existing AI risk management frameworks and practices such as:
- NIST-inspired foundation model risk management framework
- ISO/IEC 23894
- Practices explained in Koessler et al. (2023)
A substantial amount of work that RSPs has done will be helpful as a part of detailing those frameworks, but core foundational principles of RSPs are wrong and so should be abandoned.
How to move forward?
Pragmatically, I suggest a set of changes that would make RSPs more likely to be helpful for safety. To mitigate the policy and communication nefarious effects:
- Rename “Responsible Scaling Policies” as “Voluntary Safety Commitments”
- Be clear on what RSPs are and what RSPs aren’t: I propose that any RSP publication starts by “RSPs are voluntary commitments taken unilaterally done in a racing environment. As such, we think they help to improve safety. We can’t show they are sufficient to manage catastrophic risks and they should not be implemented as public policies.”
- Push for solid risk management public policy: I propose that any RSP document points to another document and says “here are the policies we think would be sufficient to manage risks. Regulation should implement those.”
To see whether already defined RSPs are consistent with reasonable levels of risks:
- Assemble a representative group of risk management experts, AI risk experts and forecasters.
- For a system classified as ASL-3, estimate the likelihood of the following questions:
- What’s the annual likelihood that an ASL-3 system be stolen by {China; Russia; North Korea; Saudi Arabia; Iran}?
- Conditional on that, what are the chances it leaks? it be used to build bioweapons? it be used for cyber offence with large-scale effects?
- What are the annual chances of a catastrophic accident before ASL-4 evaluations trigger?
- What are the annual chances of misuse catastrophic risks induced by an ASL-3 system?
- Share the methodology and the results publicly.
Meta
Epistemic status: I've been looking into various dangerous industries safety standards for now about 4-6 months, with a focus on nuclear safety. I've been doing AI standardization work in standardization bodies (CEN-CENELEC & ISO/IEC) for about 10 months, along risk management experts from other domains (e.g. medical device, cars). In that context, I've read the existing AI ISO/IEC SC42 and JTC21 standards and started trying to apply them to LLMs and refining them. On RSPs, I've spent a few dozen hours reading the docs and discussing those with people involved and around it.
Tone: I hesitated in how charitable I wanted this piece to be. One the one hand, I think that RSPs is a pretty toxic meme (see Section 4) that got rushed towards a global promotion without much epistemic humility over how it was framed, and as far as I've seen without anyone caring much about existing risk management approaches. In that sense, I think that it should strongly be pushed back against under its current framing.
On the other hand, it's usually nice to try to not use negative connotations and calm discussion to move forward epistemically and constructively.
I aimed for something in-between, where I did emphasize with strong negative connotations what I think are the worst parts, while focusing on remaining constructive and focusing on the object-level in many parts.
This mixture may have cause me to land in an uncanney valley, and I'm curious to receive feedback on that.
Section 1: General Considerations on AI Risk Management
Risk management is about demonstrating that risks are below acceptable levels. Demonstrating the absence of risks is much more difficult than showing that some risks are dealt with. More specifically, the less you understand a system, the harder it is to rule out risks.
Let’s take an example: why can we prove more easily that the chances that a nuclear power plant causes a large-scale catastrophe are <1 / 100 000 while we can’t do so with GPT-5? In large part because we now understand nuclear power plants and many of their risks. We know how they work, and the way they can fail. They’ve turned a very unstable reaction (nuclear fission) into something manageable (with nuclear reactors). So the uncertainty we have over a nuclear power plant is much smaller than the one we have on GPT-5.
One corollary is that in risk management, uncertainty is an enemy. Saying “we don’t know” is a failure. Ruling out risks confidently requires a deep understanding of the system and disproving with very high confidence significant worry. To be clear: it is hard. In particular when the operational domain of your system is “the world”. That’s why safety is demanding. But is that a good reason to lower our safety standards when the lives of billions of people are at stake? Obviously no.
One could legitimately say: Wait, but there’s no risk in sight, the burden of proof is on those that claim that it’s dangerous. Where’s the evidence?
Well, there’s plenty:
- Bing threatened users when deployed after having been beta tested for months.
- Providers are unable to avoid jailbreak or ensure robustness neither in text nor in image.
- Models show worrying scaling properties.
One could legitimately say: No, but it’s not catastrophic, it’s not a big deal. Against this stance, I’ll quote the famous physicist R. Feynman reflecting on the Challenger disaster in rocket safety, a field with much higher standards than AI safety:
- “Erosion and blow-by are not what the design expected. They are warnings that something is wrong. The equipment is not operating as expected, and therefore there is a danger that it can operate with even wider deviations in this unexpected and not thoroughly understood way. The fact that this danger did not lead to a catastrophe before is no guarantee that it will not the next time, unless it is completely understood.”
One could finally hope that we understand the past failures of our systems. Unfortunately, we don’t. We not only don’t understand their failure; we don’t understand how and why they work in the first place.
So how are we supposed to deal with risk?
Risk management proposes a few step methods that I’ll describe below. Most industries implement a process along those lines, with some minor variations and a varying degree of rigor and depth according to the level of regulation and type of risks. I’ll put a few tables on that in a table you can check in the Annex.
Section 2: What Standard Risk Management Looks Like
Here’s a description of the core steps of the risk management process. Names vary between frameworks but the gist of it is contained here and usually shared across frameworks.
- Define risk appetite and risk tolerance: Define the amount of risks your project is willing to incur, both in terms of likelihood or severity. Likelihood can be a qualitative scale, e.g. referring to ranges spanning orders of magnitude.
- Risk identification: Write down all the threats and risks that could be incurred by your project, e.g. training and deploying a frontier AI system.
- Risk assessment: Evaluate each risk by determining the likelihood of it happening and its severity. Check those estimates against your risk appetite and risk tolerance.
- Risk treatment: Implement changes to reduce the impact of each risk until those risks meet your risk appetite and risk tolerance.
- Monitoring: During the execution of the project, monitor the level of risk, and check that risks are indeed all covered.
- Reporting: Communicate the plan and its effectiveness to stakeholders, especially those who are affected by the risks.
What’s the point of those pretty generic steps and why would it help AI safety?
(1) The definition of risk thresholds is key 1) to make commitments falsifiable & avoid goalpost moving and 2) to keep the risk-generating organization accountable when other stakeholders are incurring risks due to its activity. If an activity is putting people’s lives at risk, it is important that they know how much and for what benefits and goals.
- Here’s what it looks like in nuclear for instance, as defined by the Nuclear Regulatory Commission:

2. The UC Berkeley Center for Long-Term Cybersecurity NIST-inspired risk management profile for General-purpose AI systems co-written with D. Hendrycks provides some thoughts on how to define those in Map 1.
(2) Risk identification through systematic methods is key to try to reach something as close as possible from a full coverage of risks. As we said earlier, in risk management, uncertainty is a failure and a core way to substantially reduce it is to try to be as comprehensive as possible.
- For specific relevant methods, you can find some in Section 4 of Koessler et al. 2023.
(3) Risk assessment through qualitative and quantitative means allows us to actually estimate the uncertainty we have. It is key to then prioritize safety measures and decide whether it’s reasonable to keep the project under its current forms or modify it.
- An example of a variable which is easy to modify and changes the risk profile substantially is the set of actuators an AI system has access to. Whether a system has a coding terminal, an internet access or the possibility to instantiate other AI systems are variables that substantially increase its set of actions and correspondingly, its risk.
- For specific relevant methods, you can find some in Section 5 of Koessler et al. 2023. Methods involving experts’ forecasts like probabilistic risk assessment or Delphi techniques already exist and could be applied to AI safety. And they can be applied even when:
- Risk is low (e.g. the Nuclear Regulatory Commission requires nuclear safety estimates of probabilities below 1/10 000).
The US Nuclear Regulatory Commission (NRC) specifies that reactor designs must meet a theoretical 1 in 10,000 year core damage frequency, but modern designs exceed this. US utility requirements are 1 in 100,000 years, the best currently operating plants are about 1 in one million and those likely to be built in the next decade are almost 1 in 10 million. |
b. Events are very fat-tailed and misunderstood, as was the case in nuclear safety in the 1970s. It has been done, and it is through the iterative practice of doing it that an industry can become more responsible and cautious. Reading a book review of Safe Enough?, a book on the history of quantitative risk assessment methods used in nuclear safety, there’s a sense of déjà-vu:
If nuclear plants were to malfunction at some measurable rate, the industry could use that data to anticipate its next failure. But if the plants don't fail, then it becomes very difficult to have a conversation about what the true failure rate is likely to be. Are the plants likely to fail once a decade? Once a century? Once a millennium? In the absence of shared data, scientists, industry, and the public were all free to believe what they wanted. Astral Codex Ten, 2023, describing the genesis of probabilistic risk assessment in nuclear safety. |
(4) Risk treatment is in reaction to the risk assessment and must be pursued until you reach the risk thresholds defined. The space of interventions here is very large, larger than is usually assumed. Better understanding one’s system, narrowing down its domain of operation by making it less general, increasing the amount of oversight, improving safety culture: all those are part of a broad set of interventions that can be used to meet thresholds. There can be a loop between the treatment and the assessment if substantial changes to the system are done.
(5) Monitoring is the part that ensures that the risk assessment remains valid and nothing major has been left out. This is what behavioral model evaluations are most useful for, i.e. ensuring that you track the risks you’ve identified. Good evaluations would map to a pre-defined risk appetite (e.g. 1% chance of >1% deaths) and would cover all risks brought up through systematic risk identification.
(6) Reporting is the part that ensures that all relevant stakeholders are provided with the right information. For instance, those incurring risks from the activities should be provided with information on the amount of risk they’re exposed to.
Now that we’ve done a rapid overview of standard risk management and why it is relevant to AI safety, let’s talk about how RSPs compare against that.
Section 3: RSPs vs Standard Risk Management
Some underlying principles of RSPs should definitely be pursued. There are just better ways to pursue these principles, that already exist in risk management, and happen to be what most other dangerous industries and fields do. To give two examples of such good underlying principles:
- stating safety requirements that companies have to reach, without which they can’t keep going.
- setting up rigorous evaluations and measuring capabilities to better understand if a system is good; this should definitely be part of a risk management framework, but probably as a risk monitoring technique, rather than as a substitute for risk assessment.
Below, I argue why RSPs are a bad implementation of some good risk management principles and why that makes the RSP framework inadequate to manage risks.
Direct Comparison
Let’s dive into a more specific comparison between the two approaches. The International Standards Organization (ISO) has developed two risk management standards that are relevant to AI safety, although not focused on it:
- ISO 31000 that provides generic risk management guidelines.
- ISO/IEC 23894, an adaptation of 31000 which is a bit more AI-specific
To be clear, those standards are not sufficient. They’re considered weak by most EU standardization actors or extremely weak by risk management experts from other industries like the medical device industry. There will be a very significant amount of work needed to refine such frameworks for general-purpose AI systems (see a first iteration by T. Barrett here, and a table of how it maps to ISO/IEC 23894 here) But those provide basic steps and principles that, as we explained above, are central to adequate risk management.
In the table below, I start from the short version of ARC Evals’ RSP principles and try to match the ISO/IEC 31000 version that most corresponds. I then explain what’s missing from the RSP version. Note that:
- I only write the short RSP principle but account for the long version.
- There are many steps in ISO/IEC 31000 that don’t appear here.
- I italicize the ISO/IEC version that encompasses the RSP version.
The table version:
| RSP Version (Short) | ISO/IEC 31000 Version | How ISO improves over RSPs |
Limits: which specific observations about dangerous capabilities would indicate that it is (or strongly might be) unsafe to continue scaling?
| Defining risk criteria: The organization should specify the amount and type of risk that it may or may not take, relative to objectives.
It should also define criteria to evaluate the significance of risk and to support decision-making processes.
Risk criteria should be aligned with the risk management framework and customized to the specific purpose and scope of the activity under consideration. [...] The criteria should be defined taking into consideration the organization’s obligations and the views of stakeholders. [...] To set risk criteria, the following should be considered: — the nature and type of uncertainties that can affect outcomes and objectives (both tangible and intangible); — how consequences (both positive and negative) and likelihood will be defined and measured; — time-related factors; — consistency in the use of measurements; — how the level of risk is to be determined; — how combinations and sequences of multiple risks will be taken into account; — the organization’s capacity. | RSPs doesn’t argue why systems passing evals are safe. This is downstream of the absence of risk thresholds with a likelihood scale. For example, Anthropic RSP also dismisses accidental risks as “speculative” and “unlikely” without much depth, without much understanding of their system, and without expressing what “unlikely” means.
On the other hand, the ISO standard asks the organization to define risk thresholds, and emphasizes the need to match risk management with organizational objectives (i.e. build human-level AI). |
Protections: what aspects of current protective measures are necessary to contain catastrophic risks?
Evaluation: what are the procedures for promptly catching early warning signs of dangerous capability limits? | Risk analysis: The purpose of risk analysis is to comprehend the nature of risk and its characteristics including, where appropriate, the level of risk. Risk analysis involves a detailed consideration of uncertainties, risk sources, consequences, likelihood, events, scenarios, controls and their effectiveness.
Risk evaluation: The purpose of risk evaluation is to support decisions. Risk evaluation involves comparing the results of the risk analysis with the established risk criteria to determine where additional action is required. This can lead to a decision to: — do nothing further; — consider risk treatment options; — undertake further analysis to better understand the risk; — maintain existing controls; — reconsider objectives. | ISO proposes a much more comprehensive procedure than RSPs, that doesn’t really analyze risk levels or have a systematic risk identification procedure.
The direct consequence is that RSPs are likely to lead to high levels of risks, without noticing.
For instance, RSPs don’t seem to cover capabilities interaction as a major source of risk.
|
| Response: if dangerous capabilities go past the limits and it’s not possible to improve protections quickly, is the AI developer prepared to pause further capability improvements until protective measures are sufficiently improved, and treat any dangerous models with sufficient caution? | Risk treatment plans: Risk treatment options are not necessarily mutually exclusive or appropriate in all circumstances. Options for treating risk may involve one or more of the following: — avoiding the risk by deciding not to start or continue with the activity that gives rise to the risk; — taking or increasing the risk in order to pursue an opportunity; — removing the risk source; — changing the likelihood; — changing the consequences; — sharing the risk (e.g. through contracts, buying insurance); — retaining the risk by informed decision
Treatment plans should be integrated into the management plans and processes of the organization, in consultation with appropriate stakeholders. The information provided in the treatment plan should include: — the rationale for selection of the treatment options, including the expected benefits to be gained; — those who are accountable and responsible for approving and implementing the plan; — the proposed actions; — the resources required, including contingencies; — the performance measures; — the constraints; — the required reporting and monitoring; — when actions are expected to be undertaken and completed | ISO, thanks to the definition of a risk threshold, ensures that risk mitigation measures bring risks below acceptable levels. The lack of risk thresholds for RSPs makes the risk mitigation measures ungrounded.
Example: ASL-3 risk mitigation measures as defined by Anthropic (i.e. close to catastrophically dangerous) imply significant chances to be stolen by Russia or China (I don’t know any RSP person who denies that). What are the risks downstream of that? The hope is that those countries keep the weights secure and don’t cause too many damages with it.
|
| Accountability: how does the AI developer ensure that the RSP’s commitments are executed as intended; that key stakeholders can verify that this is happening (or notice if it isn’t); that there are opportunities for third-party critique; and that changes to the RSP itself don’t happen in a rushed or opaque way? | Monitoring and review: The purpose of monitoring and review is to assure and improve the quality and effectiveness of process design, implementation and outcomes. Ongoing monitoring and periodic review of the risk management process and its outcomes should be a planned part of the risk management process, with responsibilities clearly defined. [...] The results of monitoring and review should be incorporated throughout the organization’s performance management, measurement and reporting activities.
Recording and reporting: The risk management process and its outcomes should be documented and reported through appropriate mechanisms. Recording and reporting aims to: — communicate risk management activities and outcomes across the organization; — provide information for decision-making; — improve risk management activities; — assist interaction with stakeholders, including those with responsibility and accountability for risk management activities. | Those parts have similar components.
But ISO encourages reporting the results of risk management to those that are affected by the risks, which seems like a bare minimum for catastrophic risks.
Anthropic’s RSP proposes to do so after deployment, which is a good accountability start, but still happens once a lot of the catastrophic risk has been taken. |
Prioritized Risk Management Shortcomings of RSPs
Here’s a list of the biggest direct risk management failures of RSPs:
- Using underspecified definitions of risk thresholds and not quantifying the risk
- Claiming “responsible scaling” without including a process to make the assessment comprehensive
- Including a white knight clause that kills commitments
1. Using underspecified definitions of risk thresholds and not quantifying the risk. RSPs don't define risk thresholds in terms of likelihood. Instead, they focus straight away on symptoms of risks (certain capabilities that an evaluation is testing is one way a risk could instantiate) rather than the risk itself (the model helping in any possible way to build bioweapons). This makes it hard to verify whether safety requirements have been met and argue whether the thresholds are reasonable. Why is it an issue?
- It leaves wiggle room making it very hard to keep the organization accountable. If a lab said something was “unlikely” and it still happened, did it do bad risk management or did it get very unlucky? Well, we don’t know.
- Example (from Anthropic RSP): “A model in the ASL-3 category does not itself present a threat of containment breach due to autonomous self-replication, because it is both unlikely to be able to persist in the real world, and unlikely to overcome even simple security measures intended to prevent it from stealing its own weights.” It makes a huge difference for catastrophic risks whether “unlikely” means 1/10, 1/100 or 1/1000. With our degree of understanding of systems, I don’t think Anthropic staff would be able to demonstrate it’s lower than 1/1000. And 1/100 or 1/10 are alarmingly high.
- It doesn’t explain why the monitoring technique, i.e the evaluations, are the right ones to avoid risks. The RSPs do a good first step which is to identify some things that could be risky.
- Example (from ARC RSP presentation): “Bioweapons development: the ability to walk step-by-step through developing a bioweapon, such that the majority of people with any life sciences degree (using the AI) could be comparably effective at bioweapon development to what people with specialized PhD’s (without AIs) are currently capable of.”
By describing neither quantitatively nor qualitatively why it is risky, expressed in terms of risk criteria (e.g. 0.1% chance of killing >1% of humans) it doesn’t do the most important step to demonstrate that below this threshold, things are safe and acceptable. For instance, in the example above, why is “the majority of people with any life sciences degree” relevant? Would it be fine if only 10% of this population was now able to create a bioweapon? Maybe, maybe not. But without clear criteria, you can’t tell.
2. Claiming “responsible scaling” without including a process to make the assessment comprehensive. When you look at nuclear accidents, what’s striking is how unexpected failures are. Fukushima is an example where everything goes wrong at the same time. Chernobyl is an example where engineers didn’t think that the accident that happened was possible (someone claims that they were so surprised that engineers actually ran another real-world test of the failure that happened at Chernobyl because they doubted too much it could happen).
Without a more comprehensive process to identify risks and compare their likelihood and severity against pre-defined risk thresholds, there’s very little chance that RSPs will be enough. When I asked some forecasters and AI safety researchers around me, the estimates of the annual probability of extinction caused by an ASL-3 system (defined in Anthropic RSPs) were several times above 1%, up to 5% conditioning on our current ability to measure capabilities (and not an idealized world where we know very well how to measure those).
3. Including the white knight clause that kills commitments.
One of the proposals that striked me the most when reading RSPs is the insertion of what deserves the name of the white knight clause.
- In short, if you’re developing a dangerous AI system because you’re a good company, and you’re worried that other bad companies bring too many risks, then you can race forward to prevent that from happening.
- If you’re invoking the white knight clause and increase catastrophic risks, you still have to justify it to your board, the employees and state authorities. The latter provides a minimal form of accountability. But if we’re in a situation where the state is sufficiently asleep to need an AGI company to play the role of the white knight in the first place, it doesn’t seem like it would deter much.
I believe that there are companies that are safer than others. But that’s not the right question. The right question is: is there any company which wouldn’t consider itself as a bad guy? And the answer is: no. OpenAI, Anthropic and DeepMind would all argue about the importance of being at the frontier to solve alignment. Meta and Mistral would argue that it’s key to democratize AI to not prevent power centralization. And so on and so forth.
This clause is effectively killing commitments. I’m glad that Anthropic included only a weakened version of it in its own RSP but I’m very concerned that ARC is pitching it as an option. It’s not the role of a company to decide whether it’s fine or not to increase catastrophic risks for society as a whole.
Section 4: Why RSPs Are Misleading and Overselling
Misleading
Beyond the designation of misalignment risks as “speculative” on Anthropic RSPs and a three line argument for why it’s unlikely among next generation systems, there are several extremely misleading aspects of RSPs:
- It’s called “responsible scaling”. In its own name, it conveys the idea that not further scaling those systems as a risk mitigation measure is not an option.
- It conveys a very overconfident picture of the risk landscape.
- Anthropic writes in the introduction of its RSP “The basic idea is to require safety, security, and operational standards appropriate to a model’s potential for catastrophic risk”. They already defined sufficient protective measures for ASL-3 systems that potentially have basic bioweapons crafting abilities. At the same time they write that they are in the process of actually measuring the risks related to biosecurity: “Our first area of effort is in evaluating biological risks, where we will determine threat models and capabilities”. I’m really glad they’re running this effort, but what if this outputted an alarming number? Is there a world where the number output makes them stop 2 years and dismiss the previous ASL-3 version rather than scaling responsibly?
- Without arguing why the graph would look like that, ARC published a graph like this one. Many in the AI safety field don’t expect it to go that way, and “Safe region” oversells what RSP does. I, along with others, expect the LLM graph to reach a level of risks that is simply not manageable in the foreseeable future. Without quantitative measure of the risks we’re trying to prevent, it’s also not serious to claim to have reached “sufficient protective measures”.
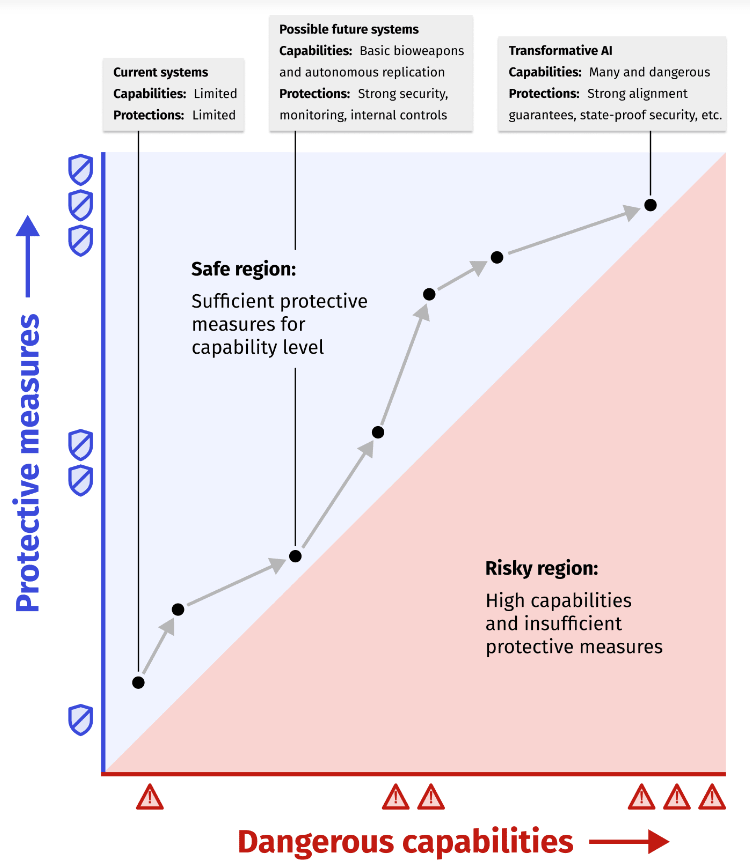
If you want to read more on that, you can read that.
Overselling, underdelivering
The RSP framework has some nice characteristics. But first, these are all already covered, in more detail, by existing risk assessment frameworks that no AI lab has implemented. And second, the coexistence of ARC's RSP framework with the specific RSPs labs implementations allows slack for commitments that are weak within a framework that would in theory allow ambitious commitments. It leads to many arguments of the form:
- “That’s the V1. We’ll raise ambition over time”. I’d like to see evidence of that happening over a 5 year timeframe, in any field or industry. I can think of fields, like aviation where it happened over the course of decades, crashes after crashes. But if it’s relying on expectations that there will be large scale accidents, then it should be clear. If it’s relying on the assumption that timelines are long, it should be explicit.
- “It’s voluntary, we can’t expect too much and it’s way better than what’s existing”. Sure, but if the level of catastrophic risks is 1% (which several AI risk experts I’ve talked to believe to be the case for ASL-3 systems) and that it gives the impression that risks are covered, then the name “responsible scaling” is heavily misleading policymakers. The adequate name for 1% catastrophic risks would be catastrophic scaling, which is less rosy.
I also feel like it leads to many disagreements that all hinge on: do we expect labs to implement ambitious RSPs?
And my answer is: given their track record, no. Not without government intervention. Which brings us to the question: “what’s the effect of RSPs on policy and would it be good if governments implemented those”. My answer to that is: An extremely ambitious version yes; the misleading version, no. No, mostly because of the short time we have before we see heightened levels of risks, which gives us very little time to update regulations, which is a core assumption on which RSPs are relying without providing evidence of being realistic.
I expect labs to push hard for the misleading version, on the basis that pausing is unrealistic and would be bad for innovation or for international race. Policymakers will have a hard time distinguishing the risk levels between the two because it hinges on details and aren’t quantified in RSPs. They are likely to buy the bad misleading version because it’s essentially selling that there’s no trade-off between capabilities and safety. That would effectively enforce a trajectory with unprecedented levels of catastrophic risks.
Section 5: Are RSPs Hopeless?
Well, yes and no.
- Yes, in that most of the pretty intuitive and good ideas underlying the framework are weak or incomplete versions of traditional risk management, with some core pieces missing. Given that, it seems more reasonable to just start from an existing risk management piece as a core framework. ISO/IEC 23894 or the NIST-inspired AI Risk Management Standards Profile for Foundation Models would be pretty solid starting points.
- No in that inside the RSPs, there are many contributions that should be part of an AI risk management framework and that would help make existing risk management frameworks more specific. I will certainly not be comprehensive, but some of the important contributions are:
- Anthropic’s RSP fleshes out a wide range of relevant considerations and risk treatment measures
- ARC provides:
- technical benchmarks and proposed operationalizations of certain types of risks that are key
- definitions of safety margins for known unknowns
- threat modelling
- low-level operationalization of some important commitments
In the short-run, given that it seems that RSPs have started being pushed at the UK Summit and various other places, I’ll discuss what changes could make RSPs beneficial without locking in regulation a bad framework.
How to Move Forward?
Mitigating nefarious effects:
- Make the name less misleading: If instead of calling it “responsible scaling”, one called it “Voluntary safety commitments” or another name that:
- Doesn’t determine the output of the safety test before having run it (i.e. scaling)
- Unambiguously signals that it’s not supposed to be sufficient or to be a good basis for regulation.
- Be clear on what RSPs are and what they aren’t. I suggest adding the following clarifications regarding what the goals and expected effects of RSPs are:
- What RSPs are: “a company that would take too strong unilateral commitments would harm significantly its chances of succeeding in the AI race. Hence, this framework is aiming at proposing what we expect to be the best marginal measures that a company can unilaterally take to improve its safety without any coordination.”. I would also include a statement on the level of risks like: “We’re not able to show that this is sufficient to decrease catastrophic risks to reasonable levels, and it is probably not.”, “we don’t know if it’s sufficient to decrease catastrophic risks below reasonable levels”, or "even barring coordinated industry-wide standards or government intervention, RSPs are only a second- (or third-) best option".
- What RSPs aren’t: Write very early in the post a disclaimer saying “THIS IS NOT WHAT WE RECOMMEND FOR POLICY”. Or alternatively, point to another doc stating what would be the measures that would be sufficient to maintain the risk below sufficient levels: “Here are the measures we think would be sufficient to mitigate catastrophic risks below acceptable levels.” to which you could add “We encourage laboratories to make a conditional commitment of the form: “if all other laboratories beyond a certain size[to be refined] committed to follow those safety measures with a reliable enforcement mechanism and the approval of the government regarding this exceptional violation of antitrust laws, we would commit to follow those safety measures.”
- Push for risk management in policy:
- Standard risk management for what is acknowledged to be a world-shaping technology is a fairly reasonable ask. In fact, it is an ask that I’ve noticed in my interactions with other AI crowds has the benefit of allowing coalition-building efforts because everyone can easily agree on “measure the risks, deal with them, and make the residual level of risks and the methodology public”.
- Standard risk management for what is acknowledged to be a world-shaping technology is a fairly reasonable ask. In fact, it is an ask that I’ve noticed in my interactions with other AI crowds has the benefit of allowing coalition-building efforts because everyone can easily agree on “measure the risks, deal with them, and make the residual level of risks and the methodology public”.
Checking whether RSPs manage risks adequately:
At a risk management level, if one wanted to demonstrate that RSPs like Anthropic’s one are actually doing what they claim to do (i.e. “require safety, security, and operational standards appropriate to a model’s potential for catastrophic risk”), a simple way to do so would be to run a risk assessment on ASL-3 systems with a set of forecasters, risk management experts and AI risk experts that are representative of views on AI risks and that have been selected by an independent body free of any conflict of interest.
I think that a solid baseline would be to predict the chances of various intermediary and final outcomes related to the risks of such systems:
- What’s the annual likelihood that an ASL-3 system be stolen by {China; Russia; North Korea; Saudi Arabia; Iran}?
- Conditional on that, what are the chances it leaks? it being used to build bioweapons? it being used for cyber offence with large-scale effects?
- What are the chances of a catastrophic accident before ASL-4 evaluations trigger?
- What are the annual chances of misuse catastrophic risks induced by an ASL-3 system?
It might not be too far from what Anthropic seems to be willing to do internally, but doing it with a publicly available methodology, and staff without self-selection or conflict of interests makes a big difference. Answers to questions 1) and 2) could raise risks so the output should be communicated to a few relevant actors but could potentially be kept private.
If anyone has the will but doesn’t have the time or resources to do it, I’m working with some forecasters and AI experts that could probably make it happen. Insider info would be helpful but mostly what would be needed from the organization is some clarifications on certain points to correctly assess the capabilities of the system and some info about organizational procedures.
Acknowledgments
I want to thank Eli Lifland, Henry Papadatos and my other NAIR colleague, Olivia Jimenez, Akash Wasil, Mikhail Samin, Jack Clark, and other anonymous reviewers for their feedback and comments. Their help doesn’t mean that they endorse the piece. All mistakes are mine.
Annex
Comparative Analysis of Standards
This (cropped) table shows the process of various standards for the 3 steps of risk management. As you can see, there are some differences but every standard seems to follow a similar structure.

Here is a comparable table for the last two parts of risk management.

Cross-posted with LessWrong.
I found this post very frustrating, because it's almost all dedicated to whether current RSPs are sufficient or not (I agree that they are insufficient), but that's not my crux and I don't think it's anyone else's crux either. And for what I think is probably the actual crux here, you only have one small throwaway paragraph:
As I've talked about now extensively, I think enacting RSPs in policy now makes it easier not harder to get even better future regulations enacted. It seems that your main reason for disagreement is that you believe in extremely short timelines / fast takeoff, such that we will never get future opportunities to revise AI regulation. That seems pretty unlikely to me: my expectation especially is that as AI continues to heat up in terms of its economic impact, new policy windows will keep arising in rapid succession, and that we will see many of them before the end of days.