“Both the cryptoeconomics research community and the AI safety/new cyber-governance/existential risk community are trying to tackle what is fundamentally the same problem: how can we regulate a very complex and very smart system with unpredictable emergent properties using a very simple and dumb system whose properties once created are inflexible?”
-Vitalik Buterin, founder of Ethereum
I think this was as true in 2016 as it still is today. And I think one approach to attacking the problem of alignment is not just by combining these two communities, but combining elements of each technology and understanding.
There are two different elements to the problem of Alignment. Getting an AI to do the things we want, and being able to come to terms on what we actually want. We’ve gotta align the AI to the humans, and we also gotta align the humans to the other humans (both present and future). My idea takes from my experience in how DAOs and other mechanisms try to solve large-scale coordination failures and a different kind of reward function.
Another element where combination could work is the ideas of Futarchy, as first imagined by Robin Hanson (vote on values, bet on beliefs), and applying it to both consensus making and AI.
Policy/metric network
Humans all over the world set goals or metrics that they want to achieve. This will be in the form of something like a global DAO, with verification using something like OpenAI’s WorldCoin. These are not infinite. They are not maximum utility forever goals. They have end dates. They have set definitions by humans. Example: reduce malaria by x%.
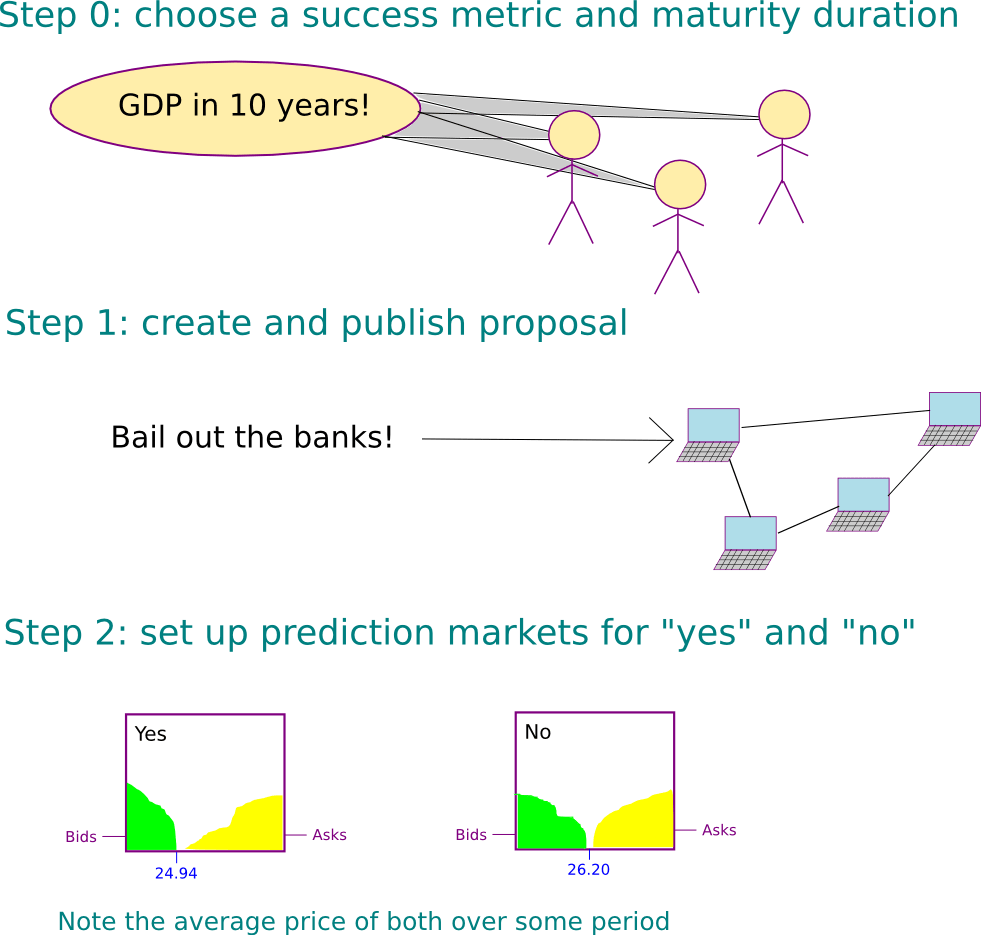
Prediction Network
We have humans make predictions about which implementations will result in the policy/metric succeeding. These predictions include predicting that humans in the future, after the policy was implemented, will approve of its implementation. These approvals will be set by the policy network after the implementation in various sequences (right after implementation, a year after, 10 years, 100 years, etc.) There is no end date for the approvals continuing. There is no point where it will be totally safe for deception, in other words. An AI will be trained on the data from this prediction network. The AI on this prediction network never stops training. It is always continuing its training run.
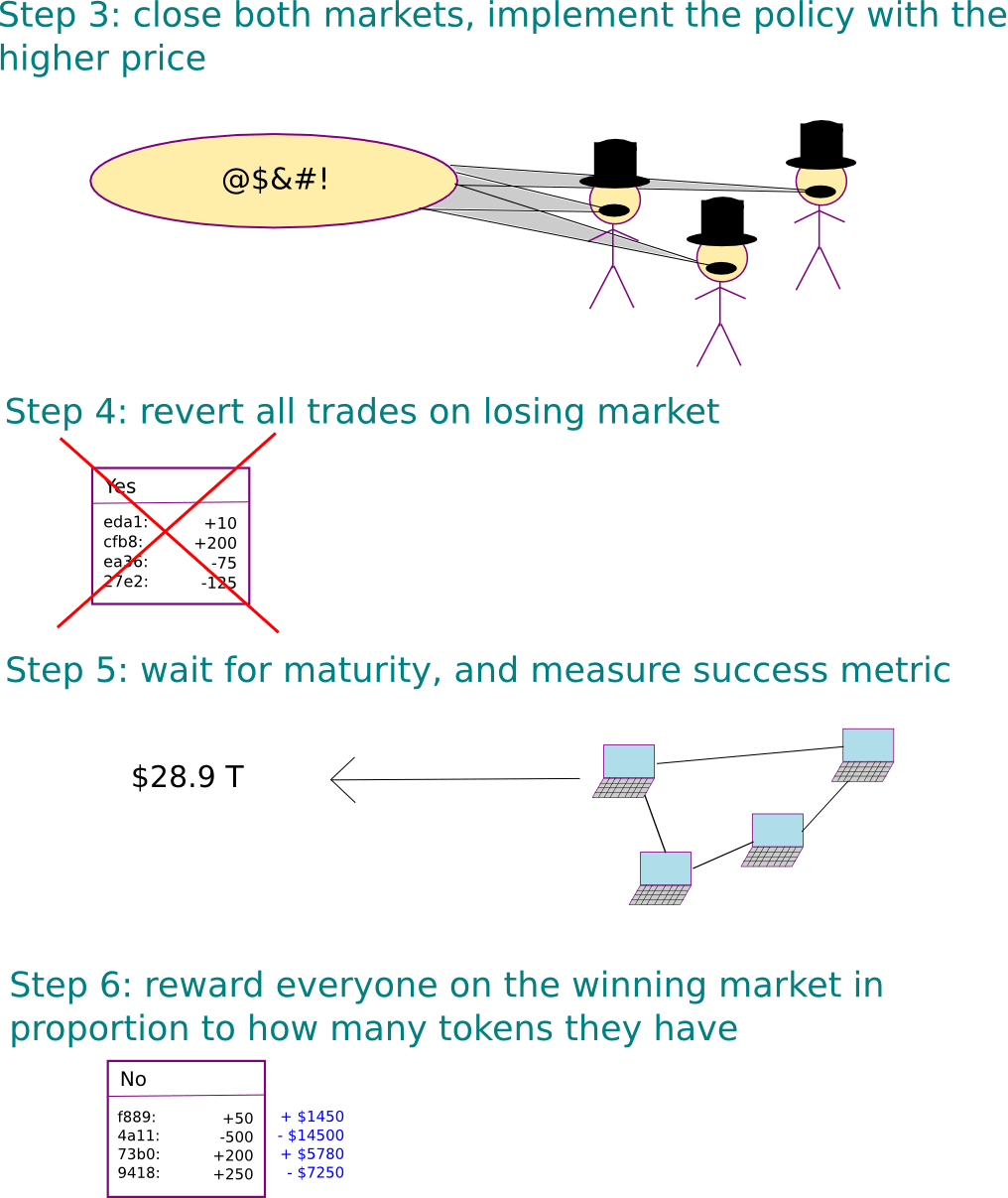
The network generalizes to assume approvals in the future, and can measure the gaps between each process.
The approvals start at very fast intervals, perhaps minutes, before getting further and further apart. The process never ends. There will always be approvals for the same policies in the future. Perhaps being trained on the network data from the past of the human prediction network could help with this generalization. This does run the risk of it just trying to imitate what a human prediction network would do, however.
Why major AI Labs and the public might change as a result of this
I think many major AI Labs (to a degree) are actually thinking about the longterm future, and the concerns that come with it, and want good outcomes. My approach keeps all humans in-the-loop on this consensus-building process, so that they are not also left out. I think starting work on this early is better than waiting for the problem to arise later. I do not expect a world where humans regret *not* working on this problem sooner.
This is a work-in-progress
I don’t see many trying to hit alignment from this angle, and I imagine a lot of this will be changed, or added to. But I think it could be a foundation to build a system that can handle an increasing amount of chaos from increases in intelligence. One stable equilibrium is all humans dying, and it seems the least complex return to stasis. But this implementation could be the groundwork for building another equilibrium.
Why I chose this
This is an extremely neglected problem. Part of my concern is aligning humans with AI, but I am also concerned with aligning humans so that humans do not double-cross or resort to violence against each other for power-seeking. Another concern I have, with the first two concerns are solved, is locking us into a future we'll actually end up regretting. My endeavor with this is to make progress on aligning AIs with longterm human interests, reduce the threat of violence between humans, and give humans more freedom post-ASI to have control over their own future.
Potential Short-Term Testing
Starting out would probably involve first figuring out the game theory, architecture, and design of the process better. Then it might involve creating a test network, with various people participating in the Policy/Metric Network, and others in the Prediction Network, and training an AI on this data. The prediction network would use fake money, without the tokens being tradable, for legal reasons. The AI would obviously not be a superintelligence, or anything close, but it might give us some insights of how this might obviously fail.
The initial architecture would be using some form of a DAO structure for the Policy/Metric network, with a prediction market for the other network. The AI would probably be built using Pytorch. It would be optimized to reduce inaccuracy of how human's will rate policies in the future.
Limitations to current testing
We don't have an AI with longterm planning skills. Most AIs currently seem very myopics, without much foresight. The AI would also not be "grounded" with a real-world model, so it's modeling of future events would not be very good. The main goal of this is to start to build on how an architecture for this might look in the future, not a solution that can be implemented now.
Next steps
I will start off by developing my own insights and design better, getting feedback from those who have a good knowledge base for this sort of approach. After that, I might bring someone on part-time to work with me on this.
Would this address RSI?
I’m not sure. I think this sort of system building would favor slower takeoffs. It’s about creating a new system that can handle the continued escalation of option space (power) and maintain some stability. A lot of this isn’t worked out yet. It could be all hold a ‘piece’ of the large system, but the piece is useless on its own. Or if agents do get out into the wild, it could be some form of aggregating agents, so that the accumulation of the agents is always stronger than any smaller group of them. It’s also possible a major policy from the network could be to detect or prevent RSIs from emerging.
Wouldn’t this lead to wireheading?
I don’t really think wireheading is likely in most scenarios. I might give this a 5% chance of wireheading or some form of reward hacking. I’d probably place a higher chance that there could be a gradual decay of our own ability to assess approval.
What about proxy goals?
Proxy goals are easily the biggest concern here. But it’s being optimized to reduce inaccuracy, and all proxy goals would still need to fulfill that. Things don’t really ever move out of distribution. I think, if takeoffs are faster, the proxy goals become a much greater threat. A slower increase in intelligence I think has a better chance of aligning the proxy goals to our interests. And it is continuously being updated on its weights, based on input from approval policies, which could allow for a sort of ‘correcting’ mechanism if the proxies start to stray too far.
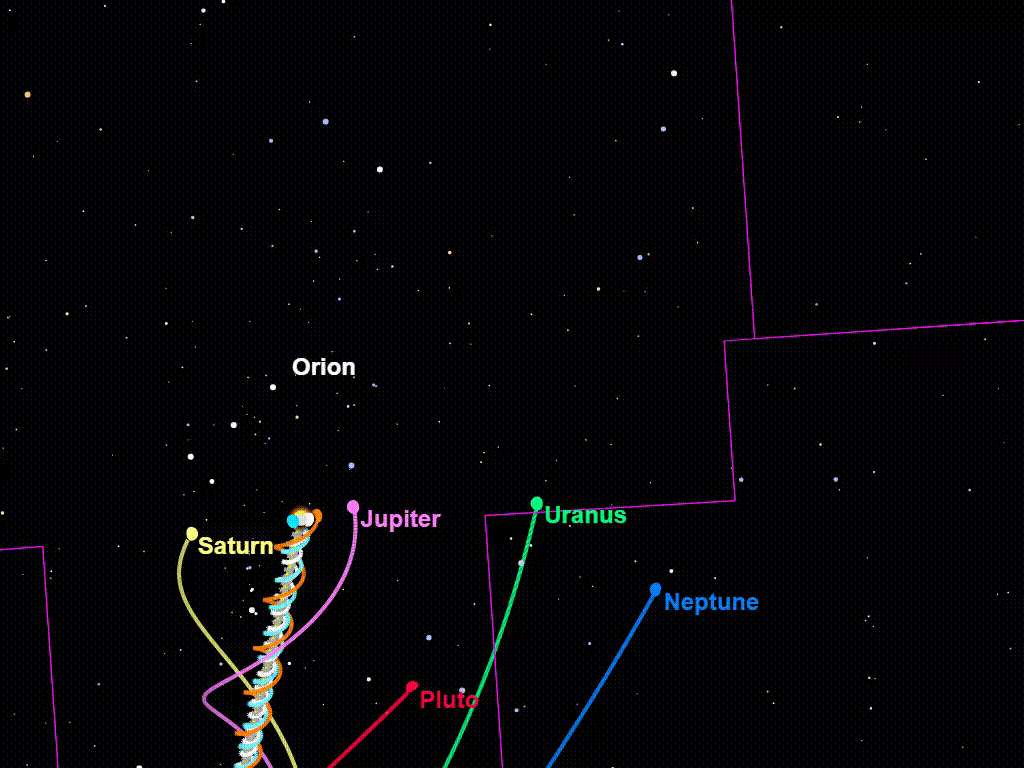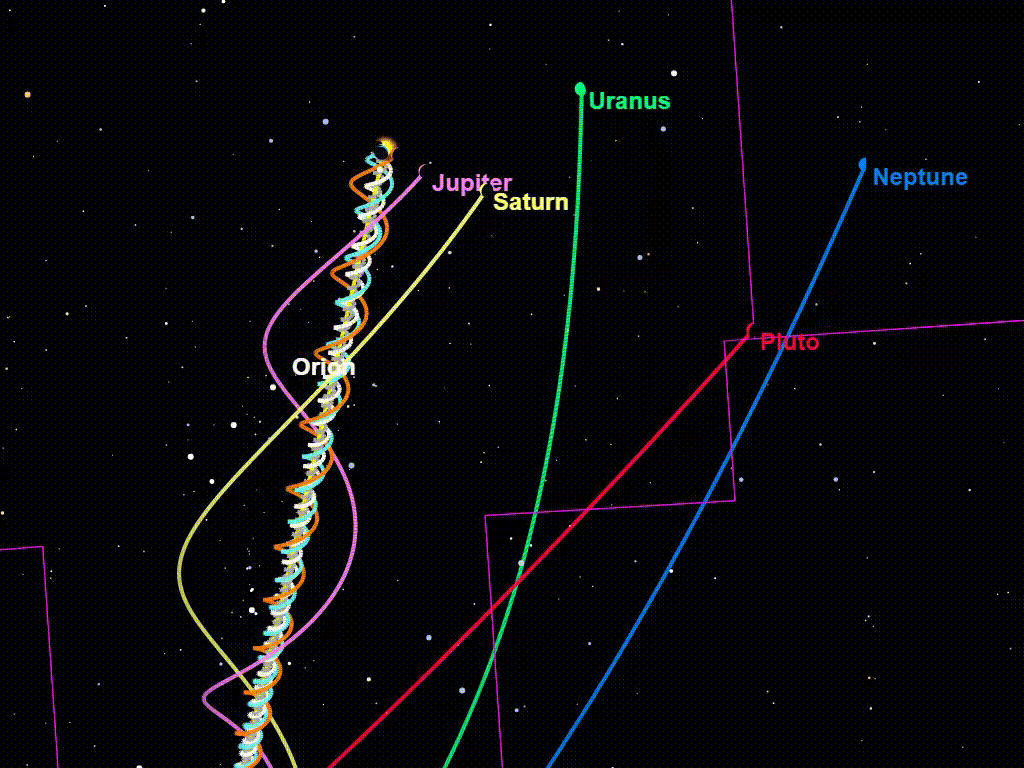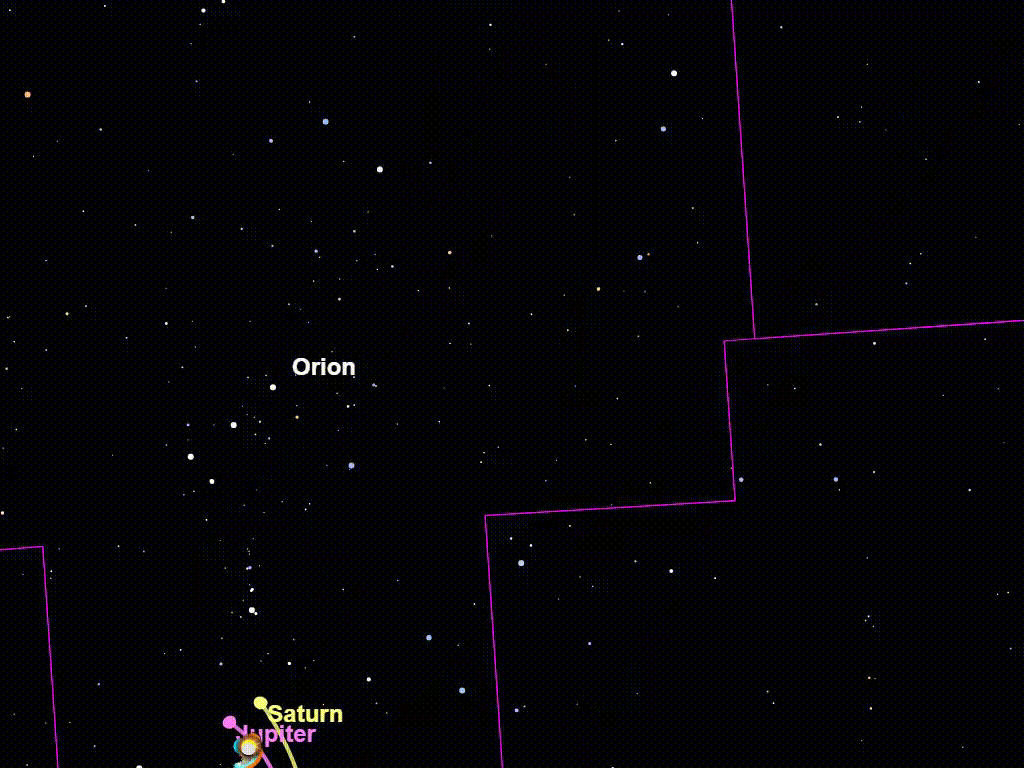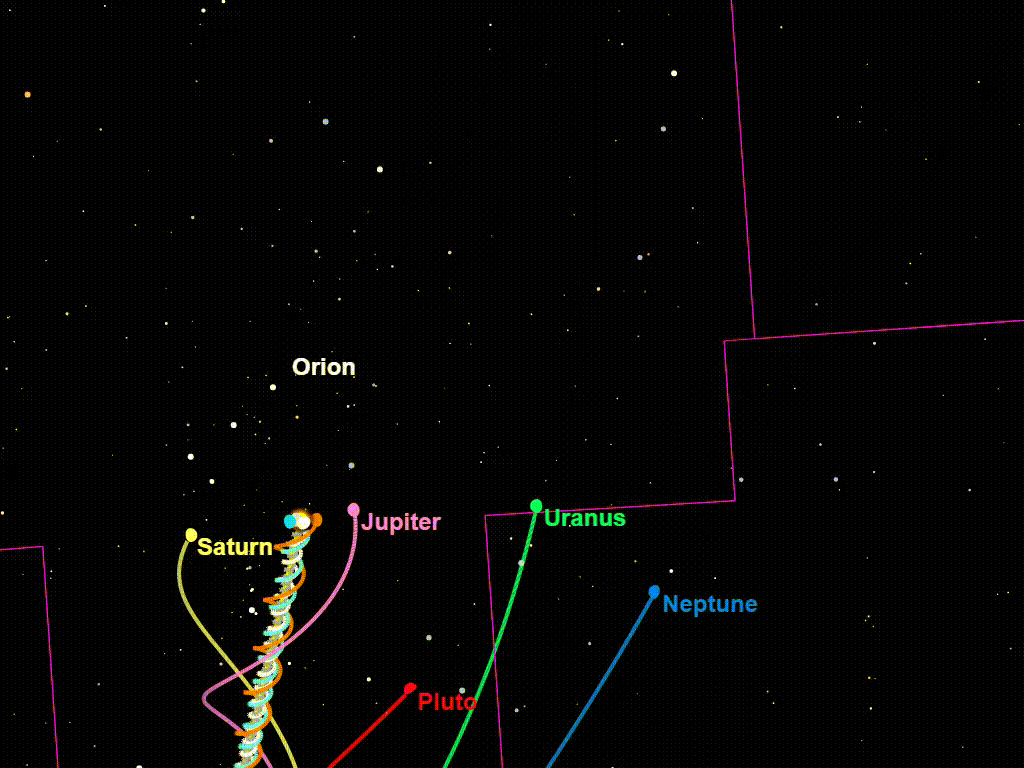
Think of the image above of the sun veering through the galaxy, with the planets orbiting around it. The sun is the optimization process, and the planets are the proxies. The planets sometimes veer away from the sun, but gravity keeps them coming back, so that they never veer too far away from it. Closer orbits are obviously safer than more distant orbits (it’d be better if the proxies were like Earth/Mars/Mercury/Venus distant instead of Neptune/Uranus distant). Since approvals will be between short timeframes at the beginning, and there will always be new policies to approve, this might keep the proxies in close-enough orbit not to do anything that would cause significant harm. And overtime, the proxies should change and become more and more closely tied to the loss function.
Would this be agentic?
That depends on the execution phase. That’s the critical part, and not sure what exactly that would look like without involving high risk. I’m not sure if the execution phase actually has to be AI, or just humans executing on a plan. But it needs to be strong-enough to outcompete whatever current other intelligent systems are out there. And it would continuously have to outcompete them, meaning its power or speed might have to increase overtime, which might make using solely humans difficult. Maybe it’ll be executed by many agents, run everywhere, with consensus mechanisms in place to safeguard against rogues. A rogue agent could be identified to not be following the plan of the policy, and all other agents could then collectively act against it.
Work to be done
There are probably many ways this could fail. But I think this is attacking the problem from a completely different angle than most are currently doing. I think a lot of progress can be made on this with more work. It also helps solve the human-alignment problem, where trying to seize the AI for your own control would be more difficult with this kind of network, and it allows humans to continue to have their own agency into the future (removing the threat of value lockin). What is great for humans now might not be great for us a thousand years from now. This gives us the chance to be wrong, and still succeed.
My current analysis is that this approach is kind of awful. But most approaches are kind of awful right now. In a few months or years, this approach might change to being just ‘slightly awful’, and then get upgraded to ‘actually okay’. ‘Actually okay’ is far better than anything we currently have, and it’s a moonshot. I’m not harboring any delusions that this is the ‘one true approach’. But, if it actually worked, I think this sort of superintelligence is the sort of future I’d be much more happy with. We don’t lose complete control. We don’t have to figure out what fundamental values we want to instill on the Universe right away. And it’s something we can build on overtime.