In the past, I have researched how we can effectively pool the predictions of many experts. For the most part, I am now focusing on directing Epoch and AI forecasting.
However, I have accumulated a log of research projects related to forecasting. I have the vague intention of working on them at some point, but this will likely be months or years. Meanwhile, I would be elated if someone else took my ideas and developed them.
And with the Million Predictions Hackathon by Metaculus looming, now seems a particularly good moment to write down some of these project ideas.
Compare different aggregation methods
Difficulty: easy
The ultimate arbiter of what aggregation works is what performs best in practice.
Redoing a comparison of forecast aggregation methods on Metaculus / INFER / etc questions would be helpful data for that purpose.
For example, here is a script I adapted from Simon M to compare some aggregation methods, and the results I obtained:
| Method | Weighted | Brier | -log | Questions |
|---|---|---|---|---|
| Neyman aggregate (p=0.36) | Yes | 0.106 | 0.340 | 899 |
| Extremized mean of logodds (d=1.55) | Yes | 0.111 | 0.350 | 899 |
| Neyman aggregate (p=0.5) | Yes | 0.111 | 0.351 | 899 |
| Extremized mean of probabilities (d=1.60) | Yes | 0.112 | 0.355 | 899 |
| Metaculus prediction | Yes | 0.111 | 0.361 | 774 |
| Mean of logodds | Yes | 0.116 | 0.370 | 899 |
| Neyman aggregate (p=0.36) | No | 0.120 | 0.377 | 899 |
| Median | Yes | 0.121 | 0.381 | 899 |
| Extremized mean of logodds (d=1.50) | No | 0.126 | 0.391 | 899 |
| Mean of probabilities | Yes | 0.122 | 0.392 | 899 |
| Neyman aggregate (o=1.00) | No | 0.126 | 0.393 | 899 |
| Extremized mean of probabilities (d=1.60) | No | 0.127 | 0.399 | 899 |
| Mean of logodds | No | 0.130 | 0.410 | 899 |
| Median | No | 0.134 | 0.418 | 899 |
| Mean of probabilities | No | 0.138 | 0.439 | 899 |
| Baseline (p = 0.36) | N/A | 0.230 | 0.652 | 899 |
It would be straightforward to extend this analysis with new questions that have been resolved since then, other datasets or new techniques.
Literature review of weight aggregation
Difficulty: easy
When aggregating forecasts, we usually resort to formulas like , where are the individual predictions (expressed in odds) and the weights assigned to each prediction.
Right now I have a lot of uncertainty about what are the best theoretical and empirical approaches to assigning weights to predictions. These could be based on factors like the date of the prediction, the track record of the forecaster or other factors.
The first step would be to conduct a literature review of schemes to weigh experts' predictions when aggregating and comparing them using Metaculus data.
Here is a relevant paper on weighted aggregation to get started with such a review.
An accessible introduction to the Fisher–Tippett–Gnedenko theorem
Difficulty: easy
This theorem should be more widely known. It is analogous to the central limit theorem, but for the case of repeated maximization.
Understanding this theorem better would help in choosing the right shape of distribution when forecasting.
Here I wrote a basic explainer of some universal distributions, covering the three limit distributions of this theorem.
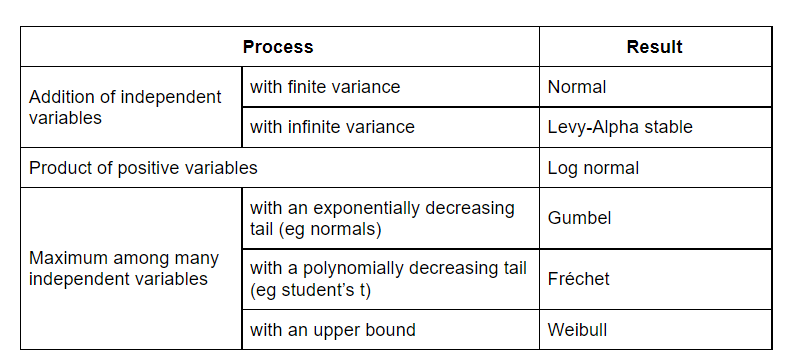
Comparing methods for predicting base rates
Difficulty: medium
Using historical data is always a must when forecasting.
While one can rely on intuition to extract lessons from the past, it is often convenient to have some rules of thumb that inform how to translate historical frequencies to base-rate probabilities.
The classical method in this situation is Laplace's rule of succession. However, we showed that this method gives inconsistent results when applying it to observations over a time period, and we proposed a fix here.
| Number of observed successes S during time T | Probability of no success during t time |
| S=0 | |
if the sampling time period is variable if the sampling time period is fixed |
While theoretically appealing, we did not show that employing this fix actually improves performance, so there is a good research opportunity for someone to collect data and investigate this.
Write a literature review of long-tail distributions
Difficulty: medium
There are dozens of competing definitions of long-tail distributions, and it is not clear what are the ones most relevant for forecasting and quantifying impact in the world.
I wrote some desiderata about what a definition should satisfy. Writing a survey of definitions would be valuable. It could include examples and the relations between different definitions.
Aggregations based on deviations from posterior
Difficulty: medium
In theory, classic aggregation methods like the geometric mean of odds perform well because they have good properties with respect to aggregating updates from a prior (eg External Bayesianity).
However, there aren't the same theoretical guarantees with respect to aggregating priors, where in theoretical settings we usually assume that experts start from the same prior. So it would be interesting to explore aggregation methods based on aggregating pure updates.
For example:
- We can take the historical resolution rate in a platform as our prior
- Then we could aggregate the updates from the experts as , where d is an extremization factor
- The final prediction would be
I tried a method like this one on Metaculus data. The results were disappointing:
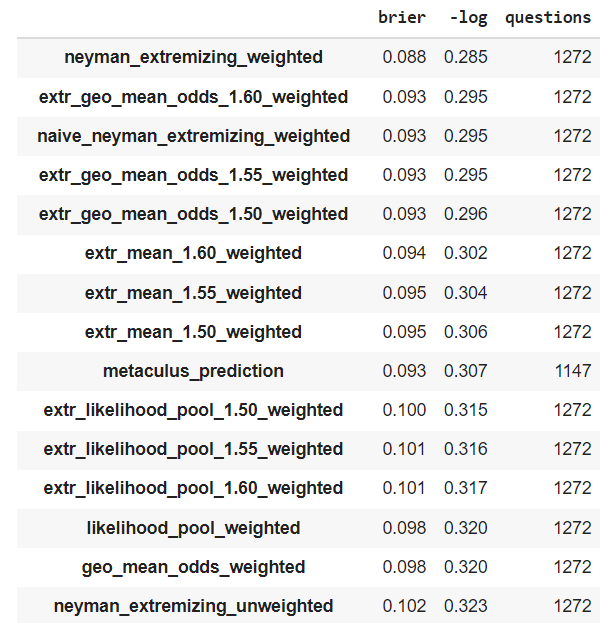
However, I might have made a mistake in the code or my conceptual analysis. I would be keen on seeing more experiments of this kind.
A method where using historical resolution rates improved the forecast is Neyman's method, which I explain here.
More sophisticated setups where you ask forecasters to elicit a prior and posterior and aggregate those separately might be promising to explore too.
Decay of predictions
Difficulty: hard
Imagine I predict that no earthquakes will happen in Chile before 2024 with 60% probability today. Then in April 2023, if no earthquakes have happened, my implied probability should be lower than 60%.
Theoretically, we should be able to derive the implied probability under some mild assumptions (eg that the probability was uniform over time), maybe following a framework like the time-invariant Laplace's rule.
This could be used to adjust outdated predictions when aggregating forecasts and might lead to better overall performance.
EDIT: Here is some previous work by Jonas Moss.
Theoretical study of weight aggregation
Difficulty: hard
Here we would want to study a toy setting in which many experts give predictions over some binary questions, and we are tasked with finding the weighting method that optimizes the log score.
The toy setting could be some task like guessing whether a set of 10 dice rolls sums more than 30 or a hypothetical event where information is revealed over time that shifts the theoretical log odds of the event in a random walk fashion.
Here are some possible toy settings:
- The experts are revealed some evidence in advance (eg each forecaster is randomly shown some dice), and perform a noisy bayesian update on it, where the noise varies per forecaster. We have a track record of their performance on some resolved questions. This would help us study aggregation depending on the forecaster's quality/track record.
- Experts make their predictions at a random time between formulation and resolution. Over time, evidence about the toy question is revealed (eg some dice rolls are revealed), and experts perform bayesian updates on the available information. This will help study aggregation based on time.
- A combination of the previous two scenarios.
Experimenting, theoretically and/or computationally, with scenarios like these can help us understand better how we should be weighting forecasts in idealized conditions.
Studying speedrunning
Difficulty: hard
Speedrunning is an activity where players try to beat a video game as fast as possible.
I think this is a very fruitful scenario in which to study how records evolve over time. It has components of luck, improvement over time and scientific discovery.
I did some preliminary analysis of the topic here, and I prepared a script to automatically download speedrunning data here.
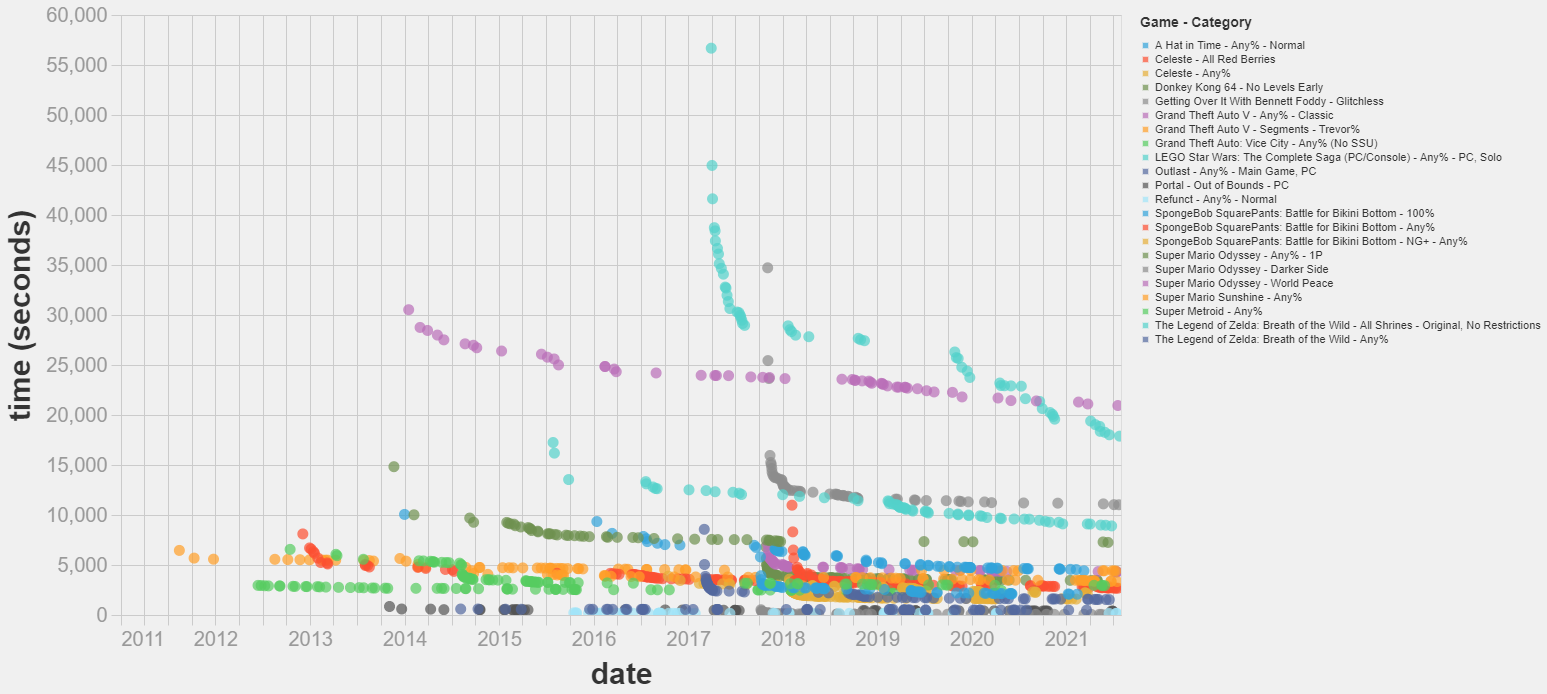
The next step I would take if researching this would be to apply the record forecasting technique we developed here. This technique assumes that there are no improvements over time, so one could try to extend the technique to model the trend of improvement.
This could include applying a log transform to the time axis to simulate exponentially more players joining over time, or combining the noise implied by the model with an extrapolation of speedrunning attempt performance.
Deriving an improved Neyman aggregator
Difficulty: hard
Neyman and Roughgarden derived an aggregation method from an adversarial theoretical setting, which I showed had great performance when aggregating forecasting log odds in Metaculus.

However, there are some limitations to their setting:
- They optimize for quadratic loss, not log loss as is usually preferred in a forecasting setting
- They constrain the family of considered aggregators to be linear, so it does not take into account eg the variance of the pooled forecasts
I think one could derive a better aggregator by relaxing these constraints.
These are all the ideas I want to share for now. Let me know if you end up pursuing any of these ideas, or if you want to discuss them!
Gradual improvements to forecasting can have a large impact on many decisions, so I am moderately excited about more research in this field. I welcome you to join me!
Your likelihood_pool method is returning Brier scores >1. How is that possible? Also, unless you extremize, it should yield the same aggregates (and scores) as regular geometric mean of odds, no?
I am so dumb I was mistakenly using odds instead of probs to compute the brier score :facepalm:
And yes, you are right, we should extremize before aggregating. Otherwise, the method is equivalent to geo mean of odds.
It's still not very good though
[I wrote this comment on LW, copying to this post. Shouldn't that happen automatically?]
Nice post! I'll throw another signal boost for the Metaculus hackathon that OP links, since this is the first time Metaculus is sharing their whole 1M db of individual forecasts (not just the db of questions & resolutions which is already available). You have to apply to get access though. I'll link it again even though OP already did: https://metaculus.medium.com/announcing-metaculuss-million-predictions-hackathon-91c2dfa3f39
There are nice cash prizes too.
As the OP writes, I think most the ideas here would be valid entries in the hackathon, though the emphasis is on forecast aggregation & methods for scoring individuals. I'm particularly interested in decay of predictions idea. I don't think we know how well predictions age, and what the right strategy for updating your predictions should be for long-running questions.
Thanks for writing this.
Thanks Jonas!