5-minute summary
| Time from GPT-3’s publication (May 2020) to… | Time | Date | Model | Organizations involved |
| A better model is produced[1] | 7 months[2] | Dec 2020 | Gopher | Deepmind |
A better or equally good model is open-sourced[3] AND A successful, explicit attempt at replicating GPT-3 is completed | 23 months (equally good model[4]) | May 2022 | OPT-175B | Meta AI Research |
Table 1: Key facts about the diffusion of GPT-3-like models
- I present my findings from case studies on the diffusion of nine language models that are similar to OpenAI’s GPT-3 model, including GPT-3 itself.[5] By “diffusion”, I mean the spread of artifacts among different actors, where artifacts include trained models, code, datasets, and algorithmic insights.[6] Diffusion can occur through different mechanisms, including open publication and replication.[7] Seven of the models in my case studies are “GPT-3-like” according to my definition, which basically means they are similar to GPT-3 in design and purpose, and have similar or better capabilities. Two models have clearly worse capabilities but were of interest for other reasons. (more)
- I think the most important effects of diffusion are effects on (1) AI timelines—the leading AI developer can get to TAI sooner by using knowledge shared by other developers, (2) who leads AI development, (3) by what margin they lead, and (4) how many actors will plausibly be contenders to develop transformative AI (TAI)[8]. The latter three effects in turn affect AI timelines and the competitiveness of AI development. Understanding cases of diffusion today may improve our ability to predict and manage the effects of diffusion in the lead up to TAI being developed. (more)
- See Table 1 for key facts about the timing of GPT-3-like model diffusion. Additionally, I’m 90% confident that no model exists which is (a) uncontroversially better than GPT-3 and (b) has its model weights immediately available for download by anyone on the internet (as at November 15, 2022). However, GLM-130B (Tsinghua University, 2022)—publicized in August 2022 and developed by Tsinghua University and the Chinese AI startup Zhipu.AI—comes very close to meeting these criteria: it is probably better than GPT-3,[9] but still requires approval to download the weights. (more)
- I’m 85% confident that in the two years since the publication of GPT-3 (in May 2020), publicly known GPT-3-like models have only been developed by (a) companies whose focus areas include machine learning R&D and have more than $10M in financial capital, or (b) a collaboration between one of these companies and either academia, or a state entity, or both. That is, I’m 85% confident that there has been no publicly known GPT-3-like model developed solely by actors in academia, very small companies, independent groups, or state AI labs.[10] (more)
- In contrast, I think that hundreds to thousands of people have enough resources and talent to use a GPT-3-like model through their own independent setup (rather than just an API provided by another actor). This is due to wider access to the model weights of GPT-3-like models such as OPT-175B and BLOOM since May 2022. (more)
- I estimate that the cost of doing the “largest viable deployment”[11] with a GPT-3-like model would be 20% of the cost of developing the model (90% CI: 10 to 68%)[12], in terms of the dollar cost of compute alone. (EDIT 25-Feb-2023: I have now updated my view on this, see this comment.) This means that deployment is most likely much less prohibitive than development. For people aiming to limit/shape diffusion, this analysis lends support to targeting interventions at the development stage rather than the deployment stage. (more)
- Access to compute appears to have been the main factor hindering the development of GPT-3-like models. The next biggest hindering factor appears to have been acquiring the necessary machine learning and engineering expertise. (more)
- The biggest factors accelerating the development of GPT-3-like models in the cases that I studied were, in order from most to least important, (1) publicity about GPT-3’s capabilities, (2) the sponsorship of compute resources,[13] and (3) the release of open-source tools for large-scale model training. (more)
- In my case studies, the diffusion of GPT-3-like models to top AI developers besides OpenAI—namely, DeepMind and Google's AI labs[14]—seemed bottlenecked by the insight of how useful GPT-3-like models are, and how predictable the benefits of scaling up language models are. (more)
- Other things that were necessary to develop a GPT-3-like model—e.g., engineering expertise, dataset collection and preprocessing, computing power—were already well within these top developers' capacity. (See key takeaway 2 in this post).
- I’m 70% confident that publication decisions for language model results by the top three language model developers (currently Google, DeepMind, and OpenAI) will become more closed on average compared to the last 3 years. While I think this is a beneficial outcome overall, I expect publication practices to still be suboptimal and worth improving via interventions.[15] (more)
- Out of the three technological inputs to AI development (compute, data, and algorithmic insights), I believe compute is the input worth the most focus when trying to differentially limit AI progress in a way that reduces AI x-risk. This is because (a) I expect that scaling of compute will continue to be crucial for AI progress in the future (even with major paradigm shifts in the way AI is developed), and (b) compute seems like the most tractable input to govern. However, I believe it is still worth the AI governance community putting some resources toward limiting both access to machine learning datasets and the spread of algorithmic insights. Below are proposals I believe are probably worth doing, but my belief has a low enough resilience that the next step should be to further consider whether or not to do them.[16] (more)
- Policy teams at AI labs should set up more discussions (in private) with top AI developers about reducing risks from the disclosure of key algorithmic insights.
- AI developers should avoid open-sourcing new large datasets, and consider providing “structured access” to datasets instead.
- Top AI developers should invest more than they currently do in the information security and operations security of their AI research and development.
20-minute summary
Background
- I present case studies of the diffusion of the 175-billion-parameter GPT-3 language model, and eight similar language models. Here, “diffusion” refers to an actor acquiring some artifact of AI research and development—e.g., a trained machine learning model.[17] Based on the case studies, I make inferences about the overall character of diffusion for large language models. More tentatively, I consider what the case studies and other research implies for the future diffusion of state-of-the-art language models, and for AI governance interventions that could reduce risks from TAI.
- I present a database containing detailed information from my case studies: Diffusion trends for GPT-3-like models. (more)
- I define terms and taxonomies that are relevant to diffusion. (more)
- “GPT-3-like model” is a term I use for a densely activated neural network model that (a) was trained to autoregressively predict text and (b) was trained using at least 1E+23 FLOPs of compute.
- This also includes a taxonomy of diffusion “mechanisms”—the means by which an actor acquires an artifact of machine learning research. The four mechanisms that were in-scope for this research project are:
- Open publication: where the artifact is made publicly available, by or with the permission of the original authors.
- Replication: where a machine learning model is trained from random initialization with an identical architecture to some existing model, and this new model has a performance differing by no more than 2% on the same benchmarks to the original model.[4]
- Incremental research: where research makes a relatively small change to an existing method, and produces a comparable or better artifact in the process.
- Multiple discovery: where two actors independently come up with the same idea or result. Considering the role of multiple discovery helps evaluate the counterfactual impact of decisions that affect diffusion.
- I focus on open publication, replication, and incremental research more than on other mechanisms of diffusion. This is because I found those mechanisms to be the most common and easiest to identify in the domain of large language model diffusion.[18] I don’t consider mechanisms like leaks by lab staff or espionage because they don’t seem to have been relevant so far. Furthermore, I focus on factors (i.e., things that enable or hinder diffusion) which seem to have been important in the diffusion of GPT-3-like models to date. (more)
- I think the most important effects of diffusion are effects on (1) AI timelines—the leading AI developer can get to TAI sooner by using knowledge shared by other developers, (2) who leads AI development, (3) by what margin they lead, and (4) how many actors will plausibly be contenders to develop transformative AI (TAI).[8] The latter three effects in turn affect AI timelines and the competitiveness of AI development. (more)
- I then give three key reasons why my research on the diffusion of GPT-3-like models in the last 2 years could inform how to reduce risks from TAI: (more)
- The way that diffusion works today (in broad terms) might persist until the development of TAI, especially if TAI is developed relatively soon (e.g., in the next 10 years).
- TAI systems (or components of them) might resemble today’s best-performing language models, especially if the scaling hypothesis is true. So the implications of diffusion related to such models may be similar to the implications of diffusion related to TAI systems.
- Even if a lot changes between now and TAI, the history of diffusion improves our understanding of what could happen.
Key takeaways
It took two years until an actor that explicitly aimed to replicate GPT-3 succeeded and published about it—why was that?
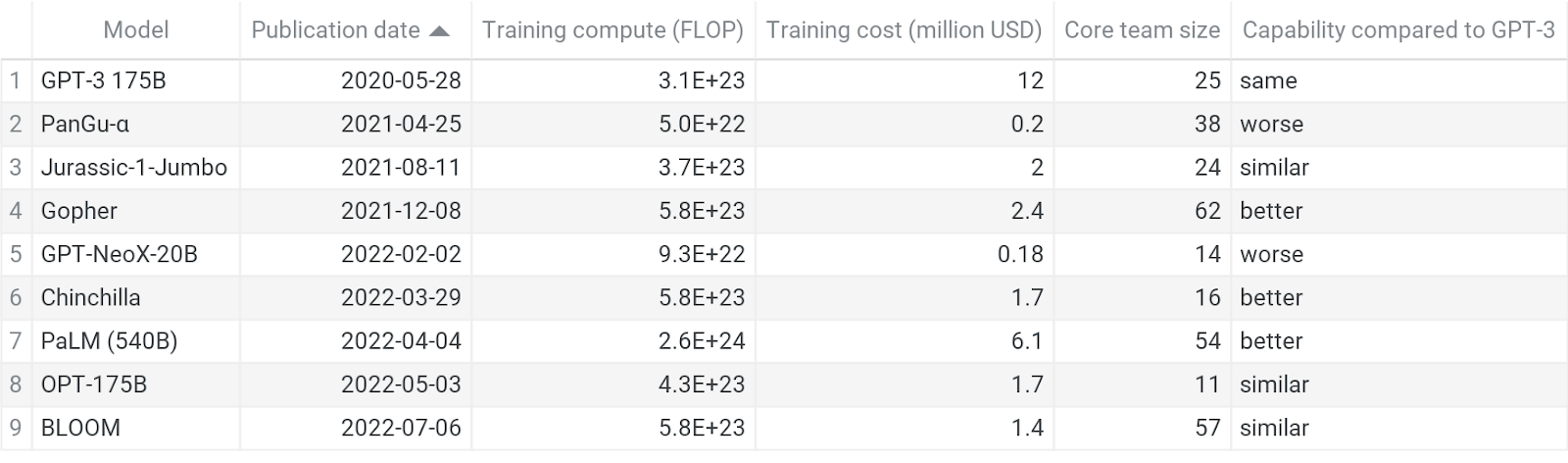
Table 2: Key information from the language model case studies. Columns from left to right: the model name, the date the model was produced, the training compute used for the final model training run in FLOPs, the actual compute cost of the final model training run (in USD), the size of the core team that developed and evaluated the model,[19] and how the model compares in performance (in a broad sense) to GPT-3.[20] Most of the data are estimates and best guesses.[21] See the diffusion database for more information on what the data mean and my reasoning process.
It took two years until an actor that explicitly aimed to replicate GPT-3 succeeded and published about it (namely, Meta AI Research publishing OPT-175B). The only other explicit replication attempt I am aware of has not succeeded; this is the GPT-NeoX project by the independent research collective EleutherAI.[22] I identified nine other models that were GPT-3-like according to my definition, which were produced as early as May 2021 and throughout the subsequent year.[23] These do not appear to be explicit replication attempts, but they are evidence of which actors are capable of replication.
- I think the main factors that made diffusion slower than it could have been were (a) the cost of compute needed to develop a GPT-3-like model and (b) the difficulty of acquiring the talent needed to develop such a model. Acquiring the necessary datasets or algorithmic insights were not significant bottlenecks, because acquiring data costs much less than acquiring compute or talent, and because most insights became publicly available. (more)
- I’m 85% confident that in the two years since the publication of GPT-3 (in May 2020), publicly known GPT-3-like models have only been developed by (a) companies whose focus areas include machine learning R&D and have more than $10M in financial capital, or (b) a collaboration between one of these companies and either academia, or a state entity, or both. That is, I’m 85% confident that there has been no publicly known GPT-3-like model developed solely by actors in academia, very small companies, independent groups, or state AI labs.[24] (more)
- I estimate the actual compute cost of the original GPT-3 final training run as $12M (90% CI: 5M–33M). Meanwhile, I estimate the actual cost of the OPT-175B final training run as $1.7M (90% CI: $1.5M–$2.3M), which is roughly seven times cheaper. Further estimates of cost and talent requirements are in Table 3.
- Part of the fall in cost is clearly due to hardware efficiency improvements (the NVIDIA A100 GPU used for OPT-175B can be up to six times more efficient than the NVIDIA V100 GPU used for GPT-3). The technical challenge to replicate GPT-3 has also decreased, which I attribute to the release of more publicly available insights and open-source software. (more)
- In addition to the above estimates, I find that following Hoffmann scaling laws (used for the Chinchilla model) leads to a roughly 3x decrease in compute cost to produce a GPT-3 equivalent, compared to using the same model size and training tokens as the original GPT-3. (more)
- I estimate that the core team developing a GPT-3-like model requires at least two years of collective experience in training language models with billions of parameters or more, including specific expertise in training efficiency and debugging for neural networks at that scale (more).
- I also considered a model where talent and compute cost are somewhat exchangeable (unlike in the above estimates). The idea of this model is that only with strong talent would you be able to train a GPT-3-like model with high hardware utilization, and minimal experiments or failed attempts, and only with strong hardware assets (namely, AI compute clusters) would you be able to minimize the price of compute (compared to cloud computing). In particular, if an actor’s total compute budget was only about $2 million (90% CI: 0.5–5), I estimate that replicating GPT-3 would require talent and hardware assets that are currently available only to the top 3–7 AI labs. Meanwhile, if an actor had a total compute budget of about $10 million (90% CI: 3–30), they could afford to fail more, have less efficient training, and less direct access to hardware. I estimate that on this larger budget, an actor would only require about four people with two years of collective full-time experience training language models with at least one billion parameters. (more)
| Estimated quantity | GPT-3 (May 2020) | OPT-175B (May 2022) |
| Actual compute cost of the final training run | $12M (90% CI: $5M–$33M) (reasoning) | $1.7M (90% CI: $1.5M–$2.3M) |
| Actual total compute cost (inc. trial and error, preliminary experiments)[25] | $49M (90% CI: $15M–$130M) (calculation) | $6M (90% CI: $4M–$10M) |
| Core team size[26] | 25 people | 11 people |
Table 3: Comparison of estimated compute costs and core team sizes for GPT-3 vs. OPT-175B, which was intended to replicate GPT-3.
GPT-3 itself can be used and fine-tuned via an API. Despite this, there’s still demand for direct access to the model’s weights, and multiple similar models now exist that provide access to weights.
- I estimate that OPT-175B can be downloaded by hundreds to thousands of ML researchers in academia, government, and industry labs, subject to approval.
- Following OPT-175B were BigScience’s BLOOM and Tsinghua’s GLM-130B, which are similar to GPT-3 but not replicas. The latter two models are publicly available for anyone to download. These are the only GPT-3-like models I am aware of up to September 2022 that are easy to directly access (i.e., anyone can download the weights of the model without the restrictions of an API).
What resources are required to actually use GPT-3-like models? How does the cost of deployment compare to the cost of development?
See the table below for my insights. The upshot is that deployment is generally much cheaper than development. (EDIT 25-Feb-2023: I have now updated my view on this, see this comment.) I think this strengthens the case for focusing on model development rather than deployment, in terms of where to target interventions on diffusion.
- One reason to care about deployment is that the use of powerful AI systems by humans could in some scenarios pose existential risk or serve as a risk factor. (more)
- Another reason is that deployment can help actors accelerate development by gaining profits, attracting investment through demonstrations, or using AI to accelerate AI R&D directly. (more)
- I mostly modeled my answer to the above question using one GPT-3-like model, BLOOM—see the results table below.
- I chose BLOOM because it is the only GPT-3-like model I was aware of (as of July 2022) that is open-source. But most of my analysis depends merely on BLOOM’s basic transformer architecture and number of parameters, so any similarly sized language model can be substituted.
- I think it’s useful to analyze who can run a model like BLOOM independently, even though there is in fact an openly accessible API for BLOOM. One can then apply a similar analysis to future models where there is a stronger incentive to run the model independently.
- I focused on a set of “deployment scenarios”—ways of deploying an AI model—that seemed like they could be very impactful, for better or worse. For example, a very large disinformation campaign.
- My analysis supports prioritizing interventions at the development stage rather than the deployment stage. Interventions targeting development seem generally more tractable because they can take advantage of the larger compute and talent barriers involved. Another reason there is more leverage at the development stage is that the developers of models seem to be in the most convenient position to deploy those same models.[28]
| Deployment scenario | Compute cost (USD)[29] | Direct talent requirement[30] |
| Generate 150 million English words by running one instance of the BLOOM model independently, for 24 hours. | 240 | One top 1% CS graduate that passed a course on natural language processing with deep learning, given three months of effort; or equivalent |
| Generate 150 million English words using GPT-3 via the OpenAI API. | 4000 | Negligible |
| Produce content equal in size to 1% of the average number of Tweets per day, for one year. Use instances of the BLOOM model running on cloud compute. | 160K (90% CI: 88K to 260K) | 5 professional software developers that have worked with ML projects, and five ML engineers who know how to run language models over multiple GPUs. Labor cost: $250K |
| Use a hypothetical GPT-3-sized coding language model to improve one million software developers’ productivity by between 1% and 10%. | 2M (90% CI: 260K to 8.4M) | 15 professional software developers that have worked with ML projects, and five ML engineers who know how to run language models over multiple GPUs. Labor cost: $500K |
| Do the largest viable deployment of a GPT-3-like model (based on above two scenarios, adjusted by other evidence).[31] | 2.6M (90% CI: 950K to 6.2M) | [not estimated] |
Table 4: Summary of deployment scenarios and the estimated requirements for them. Most of the talent requirement estimates and the final two compute cost estimates are very rough.
What have been the prevailing mechanisms and accelerating/hindering factors of diffusion for GPT-3-like models?
- Incremental research[32] was the prevailing diffusion mechanism for actors to gain direct access to the weights of a GPT-3-like model, up until the release of OPT-175B in May 2022. I identified nine GPT-3-like models that were developed as part of incremental research prior to OPT-175B, and none of them had their weights made widely accessible. The wider accessibility of OPT-175B changed the prevailing diffusion mechanism to open publication, because I estimate that there are more actors with direct access to the OPT-175B model weights than actors that have developed GPT-3-like models themselves. (more)
- I don’t think that multiple discovery was significantly involved in the diffusion of GPT-3-like models. In particular, I think if the relevant papers weren’t published, it would’ve been 6 months (90% CI: 1–18 months) before any other actor would’ve discovered either a model with GPT-3’s capabilities or the scaling laws it was based on.
- It’s plausible that the publication of the GPT-3 and scaling laws papers was unnecessarily early in terms of beating other actors to the punch, but I don’t have enough evidence to be confident in that claim. Regardless, I think that developers should have more scrutiny about whether they are really in a race to publish, because the harm of accelerating AI capabilities could outweigh the benefit of publishing first with a more responsible strategy (in order to establish better publication norms).
- I don’t think that multiple discovery was significantly involved in the diffusion of GPT-3-like models. In particular, I think if the relevant papers weren’t published, it would’ve been 6 months (90% CI: 1–18 months) before any other actor would’ve discovered either a model with GPT-3’s capabilities or the scaling laws it was based on.
- Access to compute appears to have been the main factor hindering the development of GPT-3-like models. The next biggest hindering factor appears to have been acquiring the necessary machine learning and engineering expertise. (more)
- While monetary cost is not the only measure of how significant a factor is, the following cost comparisons may be insightful:
- This Guesstimate model compares labor to compute cost for the average project to develop a GPT-3-like model. This model suggests that the total compute cost (not just the cost of the final training run) is 16x higher (90% CI: 3x to 81x) than the labor cost, which is estimated to be $1.7M (90% CI: 380K to 3.9M). However, this model just accounts for salaries, and not benefits or the cost of hiring for good enough talent in large language model training.
- My 90% CI for the cost of producing the unprocessed GPT-3 training dataset is $660K (90% CI: 270K to 1.3M). Total compute costs are thus 31x higher (90% CI: 7x to 97x) than that. See this appendix for details.
- While monetary cost is not the only measure of how significant a factor is, the following cost comparisons may be insightful:
- The biggest accelerating factors in the cases that I studied (i.e., factors that aren't necessary for developing GPT-3-like models but that seemed to make development easier or more likely) are, in order of apparent importance, (1) publicity about GPT-3’s capabilities, (2) the sponsorship of compute resources, and (3) the release of open-source tools for large-scale model training. (more)
- The diffusion of closed-source GPT-3-like models has been accelerated by incremental progress in, and open publication of, artifacts that are relevant to a given model (as opposed to just the models themselves). Relevant artifacts include datasets, smaller models, specialized software tools, and published method details (e.g., parallelism strategies). I call this process a diffusion cascade—diffusion of model-relevant artifacts begets diffusion of the model itself. Diffusion cascades can be limited by minimizing the spread of model-relevant artifacts (rather than only avoiding publishing model weights or algorithmic insights). (more)
- In addition to never publishing, delaying publication can be and has been successfully used to limit diffusion. I estimate that the publication of Brown et al. (2020) and Rae et al. (2021) was delayed by four and nine months respectively. (I’m measuring the delay from the time when the paper would have been ready to publish if the work towards publishing the paper was done as soon as possible.) Both delays seemed partly motivated by a desire to delay wide access to a powerful model. I also think that both of those delays probably did slow diffusion of GPT-3-like models significantly, though I didn’t make precise estimates about this. (more)
What publication decisions have been made for projects to develop GPT-3-like models? What were the different rationales for these decisions, and what impact did the decisions have? How will publication decisions change in the future?
- The open publication of artifacts such as training source code has had significant effects on diffusion (detailed below). But most of the effect was on actors such as Meta AI and EleutherAI, who are not leading language model developers. I think it’s more important to understand the effects of publication decisions on diffusion among the top developers—I consider the current top three to be Google, DeepMind, and OpenAI.
- Based on my case studies, it seems that prior to the publication of GPT-3, Google Research and DeepMind were bottlenecked by the insight of how useful GPT-3-like models are, and how predictable the benefits of scaling up language models are. Once they had that insight (due to knowledge of GPT-3 and its success), they proceeded to create their own GPT-3-like models (namely Gopher, Chinchilla, and PaLM). The other requirements—engineering expertise, dataset collection and preprocessing, computing power—were already well within their capacity. I don’t think that the open publication of GPT-3-related artifacts besides the above-mentioned insight had significant effects on Google’s AI labs, or DeepMind, or OpenAI.
- I’m 70% confident that going forward, publication decisions by the top three language model developers will become more closed on average. This is due to the incentives for closedness prevailing as capabilities improve. The incentives for closedness that I considered are (a) maintaining an advantage in capabilities, (b) protecting commercial IP, (c) avoiding regulation by reducing attention on capabilities, and (d) reducing both societal and public relations risk from misuse of diffused artifacts. (more)
- A key question is the publication strategy of Google’s AI labs in particular, as Google as a whole seems likely to remain one of the top developers for many years, and their publication decisions have varied greatly even in the past three years. But I’m still 65% confident that Google will open-source fewer of their best-performing language models in the future than they do today. (more)
- While I do expect publication practices from top developers to become more closed overall than they are now, this does not mean that publication practices will be anywhere near optimal. Model developers ought to recognise the potential harm from publishing all types of artifacts—algorithmic insights, training data, models, software tools, and training code (in that order of importance). Information security and the careful evaluation of the potential impacts of publication are critical to minimize harms from diffusion. I provide more detail about related interventions in the post about implications.
- In all of my case studies, details about the training process, model architecture, and hyperparameter values were openly published. This seemed to have significant effects on diffusion. (more)
- For example, EleutherAI based their choice of hyperparameter values on those of GPT-3 (which were published by the original authors) rather than doing their own hyperparameter tuning. I estimate that this decision shortened the duration of the GPT-NeoX-20B project by one month (90% CI: zero to three months).
- In general I estimate that disclosing all hyperparameter values for a GPT-3-like model saves 8% (90% CI: 1% to 20%) of the total compute cost needed to replicate that model.
- Training source code, training datasets, and trained models have been published much less than implementation details overall. Publication of these artifacts has significant effects on diffusion, but less so than algorithmic insights and implementation details. (more)
- Code for model training saves time on implementation and can reveal insights, e.g., about how to achieve better training efficiency. My best guess is that the lack of existing open-source implementations delayed EleutherAI’s GPT-NeoX-20B by two months (90% CI: one to six months), and delayed Meta AI’s OPT project by two weeks (90% CI: one to six weeks)—less time than for EleutherAI due to Meta AI probably having more resources and talent.
- I think that lack of access to large enough training datasets, and lack of open-source code to process raw data into training datasets, delayed GPT-NeoX-20B by four weeks (90% CI: one to ten weeks).
Implications of my research for forecasting and beneficially shaping the diffusion of AI technology
- If we want to beneficially shape the diffusion of AI technology in general, I think the following outcomes are both good and tractable enough to aim for. (more)
- Delay the arrival of TAI by reducing diffusion.
- Have fewer actors in the lead to develop TAI.
- Help more favorable[34] actors become leaders, or remain leaders, or increase their lead relative to less favorable actors and while ideally not speeding up AI timelines in absolute terms.
- Reduce downside risks from the last two outcomes above by supporting scrutiny towards leading actors and supporting some research outside the leading actors (mainly AI alignment research).
- The key combination of factors that limited the diffusion of GPT-3-like models was (a) that training such models required a very expensive amount of compute, and (b) that the model weights for existing GPT-3-like models were not openly published. Limiting diffusion is much easier when both of these circumstances hold. If compute cost becomes less prohibitive but models remain closed-source, then the information security and publication practices around algorithmic insights would become more important levers than they are today. Limiting diffusion seems less tractable overall in that scenario. (more)
- One way to steer diffusion in a way that reduces AI x-risk is to differentially limit access to the technological inputs of AI development—namely compute, data, and algorithms.[35] I believe it would be best to focus on differentially limiting access to compute, but to still put some resources toward differentially limiting access to data and algorithmic insights. For the sake of promoting ideas I believe to be more neglected, I do not discuss interventions for compute in this work, because they have been explored in previous work.[36] (more)
- To beneficially shape the diffusion of data, I think it would be good for leading AI developers or data curators to do the things listed below. I believe these things are probably worth doing, but that belief has a low enough resilience that the next step should be further consideration of whether or not to do these things. (more)
- Don’t open-source new big datasets.
- Set up “structured access” to datasets if there is enough demand for the data. To my knowledge this is a novel proposal[37] which would involve the owner of the dataset not sharing the dataset but still allowing users to train models on it. I think it is worth preemptively setting up structured access to datasets in case data becomes a more precious and consequently more controllable resource in the future.
- To beneficially shape the diffusion of algorithmic insights, I think the proposals below are promising. I believe these things are probably worth doing, but that belief has a low enough resilience that the next step should be further consideration of whether or not to do these things. (more)
- Initiate more discussions (in private) with top AI developers about reducing risks from the disclosure of key algorithmic insights. Researchers at Google seem like the most important people to talk to, given that Google seems to be the most well-resourced AI developer in the world, but appears to be less consistent than OpenAI and DeepMind in its publication strategy in the past three years (as discussed previously). If some top AI researchers were to initiate these discussions after carefully preparing strong arguments and clear presentations of those arguments, I would intuitively guess that there is a 20% chance (90% CI: 1 to 50%) that the discussions lead top developers to publish one less insight as important as Hoffmann scaling laws per year (I estimate that, compared to the Kaplan scaling laws that GPT-3-like models have roughly followed to date, Hoffmann scaling laws enable roughly 3 times less training compute to achieve the same performance).
- I think that top AI developers should invest more than they currently do in the information security and operations security of their AI research and development. However, I have not investigated the costs and benefits of this thoroughly enough to make more concrete recommendations.
- I generally endorse the use of structured access for AI systems that are at or beyond today’s state of the art in their domain, if there is a strong enough case for beneficial uses of the model in research or commerce. (more)
Questions for further investigation
I recommend the following topics for further investigation. Feel free to reach out to me about these research ideas. I may be able to offer advice, suggest links, and suggest people to talk to. It's possible that I or Rethink Priorities could help connect you with funding to work on these ideas if you're interested and a good fit.
- Further research to evaluate my proposals to limit access to datasets and algorithmic insights.
- What is the relevance and importance of diffusion mechanisms that were not involved in my case studies? These mechanisms include leaks, espionage, and extortion.
- Case studies of diffusion in other domains of AI.
- This would be useful both to expand the overall amount of empirical data on diffusion, and to see how well/poorly my findings generalize to other domains.
- Notable candidates for study are AlphaGo Zero (game playing domain) and DALL-E (text-image domain).
- Investigating emerging AI developers such as Stability AI who could plausibly catch up to current leaders in certain domains.
- What is the rationale behind the publication strategies of these developers?
- Will their strategies shift as their AI capabilities improve and their products become more valuable?
- Further investigation of how deployment requirements could limit diffusion.
- What resources will be required to deploy an AI system that leads to transformative impact? Who will be able to access those resources?
- How might the cost of model inference change relative to the cost of training?
- How much will different inputs to AI development contribute to AI progress?
- At various points in this sequence, I present my best guesses about the relative importance of different inputs to AI development. However, I still have a lot of uncertainty, and I think further research could reduce the uncertainty substantially.
- Other topics (see this section)
How confident should you be in my findings?
The following information is something like a long-form epistemic status. It's intended to help you calibrate your confidence in my conclusions throughout the sequence. However, I don't think it's important to read through this, because I explain my reasoning and indicate levels of uncertainty throughout the sequence.
- This sequence consists of:
- Medium to high-confidence descriptions of large language model diffusion that has happened in the last two years, and why it happened
- Low to medium-confidence predictions about the future dynamics of diffusion
- Low to medium-confidence takeaways of my research for the governance of TAI
- The findings in this sequence have the following notable limitations:
- Much of the data from my case studies is highly uncertain, with quantitative estimates often spanning an order of magnitude.
- I often generalize from just a small set of case studies that were all from the same narrow domain. Some of my conclusions are not robust to counterexamples that I might discover in future. However, I have tried my best to factor this possibility into my confidence levels.
- Many of my bottom-line conclusions are not supported by much hard evidence, and are instead based on a combination of logical arguments and intuitions.
- Most of the research was carried out April–August 2022. Writing mostly took place from September–October 2022. I then made some final adjustments from November–December 2022. This means that I am mostly not accounting for new information that has become available from September 2022 onwards.
- I tried to provide quantitative estimates wherever I had time to do so, and thought that would be clearer, easier to meaningfully critique, and perhaps more useful than providing only qualitative statements (which are often liable to a wide range of interpretations). This means I give many estimates that I have low confidence in, that are not based on much, and/or that I expect might change dramatically following further research or thought.
- The project involved roughly 500 hours of research, consisting mostly of:
- Case studies of GPT-3-like models informed by my own research from public internet sources
- My independent thinking and reasoning, in the form of estimates, forecasts, and arguments
- Interviews or email exchanges with ~30 experts, namely:
- ~13 AI governance researchers with relevant knowledge or better-informed opinions than me
- ~17 people with experience in large language model R&D
- The accuracy of my findings has been tested in the following ways. Note that I am responsible for any remaining inaccuracies in this sequence.
- ~14 external professionals in the AI governance community read the summaries and left at least one comment about something they were skeptical of or found inaccurate, which I then rectified as best I could.
- Michael Aird—Senior Research Manager on the AI Governance & Strategy team at Rethink Priorities, and my manager—reviewed the entire sequence for accuracy and reasonableness. However, Michael is not an expert in the topic and did not thoroughly vet my reasoning.
- Erich Grunewald—Research Assistant on the AI Governance & Strategy team at Rethink Priorities—reviewed the summaries and posts 4, 5, and 7 for accuracy and reasonableness. Erich did various things to check my reasoning in detail, but not comprehensively. For example, Erich played around with one of my Guesstimate models to check that it seemed reasonable.
- ~11 other people at Rethink Priorities provided a general review of various small fractions of the sequence at various stages of drafting.
- In terms of technical AI experience, I have:
- ~500 hours of experience doing research projects centered on deep learning.
- For example, one ~100 hour project was about the generalization capability of a small transformer model on worded mathematics problems.
- An MSc in Artificial Intelligence from the University of Edinburgh, including a course on natural language processing using deep learning.
- ~1500 hours of experience with software development in a collaborative machine learning research context.
- ~500 hours of experience doing research projects centered on deep learning.
- The work for this sequence was done mostly during a Fellowship at Rethink Priorities, as part of my first major AI governance research project.
- I stopped working on this when it seemed best to move on to other projects, rather than when I felt there were no obvious ways to further improve it.
Errata
- 2023-Jan-03: Corrected the publication date of OPT-175B in Table 1. (Thanks to Peter Wildeford for pointing this out.)
- 2023-Jan-23: Corrected the data in Table 2. A lot of the data in this table was incorrect due to a change in the ordering of data in the diffusion database. (Thanks to Stella Biderman for pointing this out.)
- 2023-Jan-23: It has been pointed out that given what we know now, OPT-175B is very likely to have significantly worse capability overall compared to GPT-3. The same is true of BLOOM. However, due to time constraints I have opted to leave the report as-is, which reflects my best guess at the original time of writing.
- 2023-Feb-25: I added some notices in the text to flag my updated view about the cost of compute for deployment vs. development.
Acknowledgements

This research is a project of Rethink Priorities. It was written by Ben Cottier. Thanks to Alexis Carlier, Amanda El-Dakhakhni, Ashwin Acharya, Ben Snodin, Bill Anderson-Samways, Erich Grunewald, Jack Clark, Jaime Sevilla, Jenny Xiao, Lennart Heim, Lewis Ho, Lucy Lim, Luke Muehlhauser, Markus Anderljung, Max Räuker, Micah Musser, Michael Aird, Miles Brundage, Oliver Guest, Onni Arne, Patrick Levermore, Peter Wildeford, Remco Zwetsloot, Renan Araújo, Shaun Ee, Tamay Besiroglu, and Toby Shevlane for helpful feedback. If you like our work, please consider subscribing to our newsletter. You can explore our completed public work here.
- ^
See this cell of my diffusion database for why I think Gopher performs better than GPT-3—but I think this claim is uncontroversial.
- ^
The Model Card in Appendix B of the paper published in December 2021 (Rae et al., 2021, p. 49) states the "Model Date" is December 2020, and according to the paper introducing Model Cards (Khan et al., 2022), this is the answer to "When was the model developed?".
- ^
The model weights of OPT-175B are not immediately accessible to download by anyone on the internet. However, I estimate the weights can be downloaded by hundreds to thousands of ML researchers in academia, government, and industry labs, subject to approval. Meanwhile, the training code is open-source. See this section for more information.
- ^
OPT-175B just meets my threshold for “equally good”, as it had about 2% worse accuracy than GPT-3 on average, on the 14 benchmarks that were evaluated for both GPT-3 and OPT-175B (see this cell in my diffusion database). The 2% threshold is somewhat arbitrary. I chose that threshold partly because the OPT paper itself claimed (e.g. in the Abstract) that OPT-175B performance is “comparable” to GPT-3 (Zhang et al., 2022), and partly based on my not-well-informed intuition regarding how a 2% performance difference over a few benchmarks would affect the overall usefulness of the language model.
Edited to add 2023-Jan-23: It has been pointed out that given what we know now, OPT-175B is very likely to have significantly worse capability overall compared to GPT-3. The same is true of BLOOM, which I discuss elsewhere. Due to time constraints, I have opted to leave the report as-is, which reflects my best guess at the original time of writing.
- ^
Throughout this sequence, “GPT-3” refers to the original 175-billion-parameter model that was first described in Brown et al. (2020), except in cases where I say “GPT-3” in the context of using the OpenAI API, in which case I’m referring to the latest version of the “Davinci” model provided by the API.
- ^
I have found "diffusion" and "proliferation" to be competing terms with similar meanings in the context of AI risk. I chose the term “diffusion” because it seems less value-laden. One reason that "proliferation" has been used seems to be the analogy to nuclear non-proliferation. I think this analogy can be useful, but I want to avoid drawing too strong an analogy. Although much of my motivation for writing this sequence is that diffusion of AI could increase AI existential risk, I don’t think that AI diffusion is categorically bad, and I don’t want to imply that current state-of-the-art AI technology is as dangerous as nuclear weapons.
- ^
I define replication as: a machine learning model is trained from random initialization with an identical architecture to some existing model, and this new model has a performance differing by no more than 2% on the same benchmarks to the original model. The 2% is somewhat arbitrary. I am uncertain what the best threshold is. But the impression I gained from my case studies is that a 2% difference is small enough to call the actor “capable” of replication.
- ^
I define transformative AI qualitatively as “potential future AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.” This is how Holden Karnofsky originally defined the term in 2016 (Karnofsky, 2016).
- ^
See Figure 1(a) on p.2 of Zeng et al. (2022).
- ^
It’s plausible that there have been secret projects undertaken by the intelligence community to develop GPT-3-like models, but I am not aware of any, and I haven’t tried to assess the likelihood of this.
- ^
By “largest viable deployment”, I mean the way of deploying a GPT-3-like model that has the highest volume of model outputs that (a) would be possible for at least one actor to do by now if they tried, and (b) is worth the cost in light of the actor’s goals (which may or may not be profit). For example, a large-scale automated disinformation campaign.
- ^
Throughout this sequence, I use “90% CI” to refer to my 90% confidence interval for an estimated value. That is, I believe it is 90% likely that the value lies between the first number (the lower bound) and the second number (the upper bound). I generated 90% confidence intervals in various ways depending on how I estimated the value and what evidence was available. In cases where there was no clear way to estimate a 90% CI systematically, I thought about what 90% CI I would be willing to bet on.
- ^
Sponsorship of compute resources could involve an actor doing any of the following things: (a) giving another actor ownership of compute hardware, (b) giving another actor access to compute hardware, (c) giving another actor money that can only be used on compute, or (d) giving another actor money with the intention that it is used for compute. Only (b) and (c) occurred in my case studies.
- ^
In this sequence, for simplicity, I treat Google as a single actor. But this is debatable; there are multiple teams at Google that research and develop language models (e.g., under the names “Google Brain” and “Google Research”), and these teams seem to have significant autonomy over publication decisions.
- ^
When I say “suboptimal” I don’t just mean that those developers should become even more closed than the default. I don’t have a precise idea of an optimal strategy, but I think it involves being more discerning about which artifacts are diffused, at what time, and at what level of publicity.
- ^
For the sake of promoting ideas I believe to be more neglected, I do not discuss interventions for compute in this work, because they have been explored in previous work. See e.g., the section on “Compute Governance ideas” in “Some AI Governance Research Ideas” (Anderljung & Carlier, 2021).
- ^
I conceptualize diffusion in a fuzzy way, meaning that an actor doesn’t have to acquire the exact same artifact for it to count as diffusion. An actor merely needs to acquire some artifact that serves roughly the same function as some existing artifact. For example, an actor can “replicate” a machine learning model in the sense that they train a new model from scratch that is functionally very similar to the original model.
- ^
While other mechanisms such as theft are harder to identify (because thieves usually don’t want to be known), I am still 80% confident that open publication, replication, and incremental research are the most common and most important mechanisms in my case studies. I argue this in detail in this section.
- ^
“Core team” size was based on author contributions listed in a paper. I counted people that I judged to be directly involved in producing the result (mainly the trained model). "Producing the original result" includes evaluation of the trained model on standard performance benchmarks, but not evaluation of social fairness, bias, toxicity, or broader impacts, nor pure discussion about the model. The reason is that the latter things are not directly relevant to producing the model or advancing general capabilities.
- ^
Where possible, I assess performance difference by comparing common benchmark metrics reported in the research papers for these models. However, not all of the same benchmark results are reported, and the results are not always presented in the same way (e.g., a table in one paper, but only a plot in another paper). Furthermore, models are not perfectly comparable in performance because they differ in their training compute, datasets, and model sizes—the training data in particular could differ drastically in terms of which languages are most represented and therefore which downstream tasks the model performs best at. So I also draw on other evidence to get a broad sense of “capability”, e.g., training compute, dataset size, data diversity, model size, and how the paper summarizes a model’s performance in comparison to other models.
- ^
The widths of my 90% confidence intervals in “Model date” are between one and eight months—with Gopher, OPT-175B, and BLOOM on the one-month end.
My 90% CI for training compute generally spans from 0.5 times my central estimate to two times my central estimate. This is based on the range of empirical differences found in a 2022 analysis by the AI forecasting organization Epoch (Sevilla et al., 2022). In Sevilla et al. (2022), 95% confidence intervals for the compute trends were derived from bootstrap sampling. In the sample, each compute estimate was adjusted by a random factor between 0.5 and 2 “to account for the uncertainty of [the] estimates”, based on the same analysis (see p.16). This informed my decision to use the 0.5–2x range as a 90% CI, but I also used my own intuitive judgment of the appropriate level of uncertainty.
My 90% CI for training cost generally spans from 0.4 times my central estimate to 2.7 times my central estimate.
My 90% CI for core team size is generally +/- 50% of my central estimate.
I’m generally about 80% confident in my claims about whether a given model’s capability level is worse than, similar to, or better than GPT-3’s, if you accept my broad notion of a model’s capabilities. (See the cell notes for that column in the database for more information.)
- ^
EleutherAI didn’t succeed in the sense that their best model to date, GPT-NeoX-20B, only used 5.0E+22 FLOPs of compute (compared to 3.1E+23 for GPT-3) and performed significantly worse.
- ^
Two of my case studies (PanGu-alpha and GPT-NeoX-20B) are not GPT-3-like according to my definition.
- ^
As noted above, it’s plausible that there have been secret projects undertaken by the intelligence community to develop GPT-3-like models, but I am not aware of any, and I haven’t tried to assess the likelihood of this.
- ^
This is based on both my intuition and one expert’s opinion. I estimated that the total compute budget for a project is 3 times (90% CI: 2–5 times) the final training run cost, to account for trial and error and preliminary experiments.
A researcher at an industry AI lab, who has worked with large language models, told me (paraphrasing): “It wouldn't shock me if an OOM more compute was required for investigating relative to the final training run, if learning how to develop the model from scratch. Maybe less than that…Almost certainly at least a 50-50 split in compute cost between preliminary work and the final training run.” My own read on this is that a 50-50 split seems feasible for a top language model developer, while an order of magnitude difference might correspond to an amateur group attempting replication without prior experience in training language models at the scale of billions of parameters or more.
One piece of potential countering evidence to this is that EleutherAI (who started closer to the latter scenario) only spent ~1/3 of their total compute on preliminary work and 2/3 on training for GPT-NeoX-20B (based on hours of compute expenditure reported on p.23 of Black et al. (2022)). However, Stella Biderman (one of the leading contributors to the GPT-NeoX project, as well as BLOOM) indicated that this was an exceptional case, because the GPT-NeoX team already gained a lot of experience training smaller but similar models (e.g., GPT-J), and they “probably got a bit lucky” with successfully training GPT-NeoX-20B with so little testing. (Notes on my correspondence with Stella Biderman are available upon request in this document.)
Ultimately, since I’m estimating costs for major industry developers (OpenAI and Meta AI Research), I leaned toward the 50-50 end of the range, choosing 2x as the lower bound. I intuitively chose the upper bound as 5x, because that is roughly halfway between 2x and a full order of magnitude (i.e. 10x) on a logarithmic scale. I also chose the central estimate of 3x based on a logarithmic scale.
- ^
The number of people directly involved in producing the original result. "Producing the original result" includes evaluation of the trained model on main performance benchmarks, but not evaluation of social fairness, bias and toxicity, nor broader impacts, nor pure commentary about the model. The reason is that the latter things are not directly relevant to producing the model or advancing capabilities.
- ^
- ^
Note that there are also other (perhaps stronger) reasons to focus on the model development stage.
Firstly, the forms of diffusion that help actors develop models pushes AI progress forward more than the forms of diffusion that help actors deploy models. Pushing AI progress forward is what shortens AI timelines and thereby increases AI existential risk.
Secondly, a lot of AI existential risk comes from misaligned power-seeking AI rather than misuse by humans. I expect that reducing diffusion of deployment would have a smaller effect on this source of risk.
- ^
Compute cost estimates are just based on cloud compute prices, and exclude the cost of other hardware such as a laptop to set up the cloud computing instance.
- ^
By “direct” I mean the people and skills that are required to set up the model and keep the model running in the deployment setting, excluding people that maintain software dependencies (e.g. PyTorch), or people that give advice on how to do deployment.
- ^
This means the deployment with the highest volume of model outputs that (a) would be possible for at least one actor to do by now if they tried; (b) is worth the cost—not necessarily in terms of financial revenue, but in achieving the actor's goal. See this Guesstimate model for calculations (the method is also explained in the main text).
- ^
Meaning research that makes a relatively small change to an existing method.
- ^
The link to this model is currently broken. I am working on a fix.
- ^
I have three criteria for favorability: beneficence, competence (including competence at safe and responsible AI development), and receptiveness to ideas and criticism.
- ^
I think the human input of talent is also very important but I haven’t thought about it enough to provide a clear takeaway.
- ^
See e.g., the section on “Compute Governance ideas” in “Some AI Governance Research Ideas” (Anderljung & Carlier, 2021).
- ^
This idea is inspired by the idea of “structured access” to AI systems; see Shelvane (2022).
- ^
I define transformative AI qualitatively as “potential future AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.” This is how Holden Karnofsky originally defined the term in 2016 (Karnofsky, 2016).
- ^
The 2% is somewhat arbitrary. I chose that threshold partly because the OPT paper itself claimed (e.g. in the Abstract) that OPT-175B performance is “comparable” to GPT-3 (Zhang et al., 2022), and partly based on my rough intuition of how much a 2% performance difference over a few benchmarks would affect the overall usefulness of the language model.
Your reasoning in footnote 4 is sound, but note that practitioners often complain that OPT is much worse than GPT-3 (or even GPT-NeoX) in qualitative / practical terms. Benchmark goodharting is real.
(Even so, this might be goalpost shifting, since GPT3!2022 is a very different thing from GPT3!2020.)
I also wanted to say that from talking to a bunch of people and reading ML blogs/reddits/Twitter that my impression was that OPT is much worse than GPT-3, despite similar performance on some of the benchmarks, so I think this comparison is pretty off.
https://twitter.com/sir_deenicus/status/1606360611524206592
That's a good point, but I think goalpost shifting is likely not significant in this case, which supports your original point. The OPT paper compares to "GPT-3" (or "GPT" in the plots, as shorthand I guess) for the prompting and few-shot evaluations (section 3). It says on p.3:
Also on p.3 they refer to "numbers reported by Brown et al. (2020)"
But p.3 also mentions
It sounds to me like they used the original results from Brown et al. (2020) where available, but evaluated using the Davinci API as a cross-check or fallback.
In contrast, the paper talks about "Davinci" for the evaluations in subsequent sections, so this is presumably the API version of GPT-3 that was available at the time. It says on p.5 that "We compare primarily against GPT-3 Davinci, as these benchmarks were not yet available to be included in Brown et al. (2020)." I didn't include these other evaluations (e.g. Bias and Toxicity) in my analysis; I'm just pointing this out to support my guess that the evaluations in section 3 are comparing to the original GPT-3.
Thanks for raising this. On reflection, I think if I had started this project now (including re-considering my definition of "successful replication") I probably would not have classed OPT-175B as a successful replication. I probably should flag this clearly in the post.
As noted in point 2(d) of the final section of the post, I was more-or-less sitting on this report for a few months. I made significant revisions during that period, but I was paying less attention to new evidence than before, so I missed some evidence that was important to update on.
Nitpick: your summary table gives the date "May 2020" for OPT-175B but it should be "May 2022" I think.
Pretty important detail! Thanks, I've changed it.
I know you mention this as an area for further investigation, but I wonder if it is more central to your main point -- how sensitive do you think your conclusions are to the choice of using GPT-3 as your point of reference?
For example, with DALLE-2 my understanding is that similar capabilities were obtained by much lower resource actors (Midjourney, Stable Diffusion) and I'm curious what the relevant differences are to explain the much more rapid diffusion there. (The irony in the name "Stable Diffusion" being a model resulting from diffusion is funny.)
I'm curious also if you think diffusion has differed between GPT-2 and GPT-3 and what factors you think are relevant for explaining that difference, if any? I kinda forget my history but I have a rough recollection that GPT-2 was successfully replicated faster.
In fact, I think that GPT-3 may have been surprisingly hard to replicate relative to other models, especially in light of other people's comments (and also my understanding) that OPT-175B is notably worse than GPT-3 at useful tasks. I'm curious if that's true (is GPT-3 indeed hard to replicate and is it harder than other models) and why that is (why GPT-3 appears so hard to replicate well).
Similarly, I'd also be curious if you've looked much at to what extent Anthropic has been able to replicate GPT-3? It seems like they also have (closed) access to similar models. I'd also be curious what Redwood Research has been able to create, given that I think they have substantially less resources than Anthropic, OpenAI, or Meta. I imagine some labs being in possession of non-published models might complicate your analysis somewhat?
Anthropic has the same people who originally made GPT3, so them replicating gpt3 is a different sort of diffusion than others. I'd guess they internally matched gpt3 when they'd existed for ~6 months, so mid 2021. Claude, their public beta model, has similar performance to chatgpt in conversation but is not benchmarked.
Redwood Research has not attempted to train any large language models from scratch, and hasn't even reproduced gpt-2. Redwood does have employees who've worked at OpenAI, and likely could reproduce gpt3 if needed.
I tried to qualify claims to account for using a single point of reference, e.g. just talk about pre-trained language models rather than all ML models. However, as I note in the final section of this post, my claims about the broader implications of this research have the lowest confident and resilience. It feels really hard to quantify the sensitivity overall (I'm not sure if you have a way to measure this in mind). But my off-the-cuff intuition is that if my language model case studies turn out to not at all generalise in the way that I assumed, my % likelihoods for the generalised claims throughout the sequence would change by 20 percentage points on average.
I think Shevlane (2022) is currently the best source on this topic. Unfortunately it is not very accessible due to the style of an academic thesis. But the Abstract of Chapter 2 (p.63 of the PDF) gives an idea.
I didn't explicitly compare to GPT-2 but I'd say that this section ("Diffusion can be significantly limited if (a) training compute cost is high and (b) developers don’t release their model weights; otherwise, developers need to rely more on keeping methods secret") is implicitly explaining why GPT-3's release strategy succeeded more than GPT-2's release strategy: (a) there was the opportunistic fact that GPT-3 required 2 orders of magnitude more compute to train, and (b) no (smaller) versions of the GPT-3 model were open-sourced; only an API to GPT-3 was provided.
I think the training compute requirement and hardware improvements are two key differences here. Epoch's database currently estimates the training compute of Stable Diffusion as 5E+22 FLOP (link to the spreadsheet cell). That is about 6 times smaller than the estimated FLOP for GPT-3, at 3.14E+23 FLOP.
As I said in another comment, the leap from NVIDIA V100 (used to train GPT-3) to NVIDIA A100 (used to train Stable Diffusion) seems to enable a ~6x improvement in efficiency (in turn a 6x reduction in $ cost). So as a back-of-the-envelope calculation that would put Stable Diffusion at ~36x cheaper to train than the original GPT-3 training run.
There could also be algorithmic/engineering reasons why a model like Stable Diffusion is easier to produce, but I haven't looked into that.
Gpt3 is algorithmically easier to reproduce, in the sense that it's a simpler architecture with fewer and more robust hyperparameters. It's engineering is harder to reproduce, because it needs more model parallelism. People have estimated gpt3 to cost 5M, and StableDiffusion to cost 300k, which is similar to the 36k number you quoted
Appreciated the 5-minute summary; I think more reports of this length should have two summaries, one TL;DR, the other similar to your 5 min summary.
Apologies if I could easily figure it out on my own by diving into your source material, but I'm curious what factors allowed OPT-175B to be trained about 10x as cheaply as GPT-3?
You can find my take on that in this section, but I'll put an excerpt of that here:
OPT also seems to have been trained with a higher hardware utilization rate than GPT-3 (the actual FLOP/s achieved divided by the theoretical peak FLOP/s for the hardware), if reported numbers are to be believed (only 21% for GPT-3 compared to 47% for OPT-175B). This is a smaller factor of difference compared to the hardware specs, but I think I ought to have mentioned it in the report.
As an aside, it's still pretty unclear to me how different practitioners are measuring their reported utilization rates. For example is it a single measurement at a random time during training, or an average of multiple measurements, or the maximum of multiple measurements?
Thanks for writing this. It feels useful to have these diffusion numbers. However, in practice, I am much less interested in "how much longer did it take for these other models to be built?" but "by how much did the release of GPT3 move these projects forward in time?". An answer to the latter question seems to tell us more about what we can do about diffusion and whether publications have a counterfactual effect on timelines. What is your current best guess on the latter question? [sorry if I missed this somewhere]
Hi Charlotte - as you can imagine, estimating the latter is much more difficult due to reasoning about counterfactuals. But I do have some thoughts on it in this section of a post in the sequence.
I think the key claim you'd be looking for there is:
As my 90% confidence interval shows, I'm very uncertain, but I hope this helps.