#[[IAN says:]] Here is a list of ideas for how to scale up academia:
Hire more people (who will be able to help you with your research if you have a good idea).
Hire people who are good at doing things instead of people who are good at saying things.
Use artificial intelligence (or get more people who know a lot about AI to help you).
epistemic status: I'm on the inside, so I feel I know a bit more than the median person. But still, very speculative and I'm mostly writing this to see where my logic fails.
The potential impact of academic research
I have to admit, I kind of drank the effective altruism cool-aid. I do critically questioning question all the assumptions and inferences of the community (and I don't agree with everything, not by a long shot1), but the core principles are just too obviously good and true for me. This caused a good bit of distress for me since the other love of my life (academia) appears to be everything but effective or altruistic.
So it was a surprise to read the very positive 80,000 Hours career review on the (potentially) great impact of academic research. Here's part of the conclusion:
A single outstanding researcher can move a field forward and make a significant contribution to solving key global problems. Beyond research, academics also have other avenues for impact, such as by influencing government policy, the priorities within their field, and the culture of society at large.
Now if that doesn’t sound encouraging! Examples of "outstanding researchers" with a huge altruistic impact that come to my mind are f.e. Norman Borlaug, whose discovery of the "miracle wheat" prevented the starvation of a billion people2. Also, Karikó and Weissman, whose research paved the way for the mRNA vaccines that have the potential to save lives from many more things than Covid-19. So, undoubtedly, there is potential for altruistic impact in academic research.
I still want to hedge my bets. If I’ll be an academic, I want to be an effective, altruistic academic. The logic is simple: If "more science = more good", we just need to get more science. Therefore, in this post, I’ll investigate some of the factors limiting academic research and think about how we work on these bottlenecks.
Inadequate science
There are some pretty large research institutes: the Chinese Academy of Sciences employs 60.000 researchers, the French Centre National de la Recherche Scientifique employs 15.000 researchers and the German Max Planck Society employs around 7.500 researchers (source). Those are not-small numbers, but they pale in comparison to employee numbers of Fortune 500 companies:
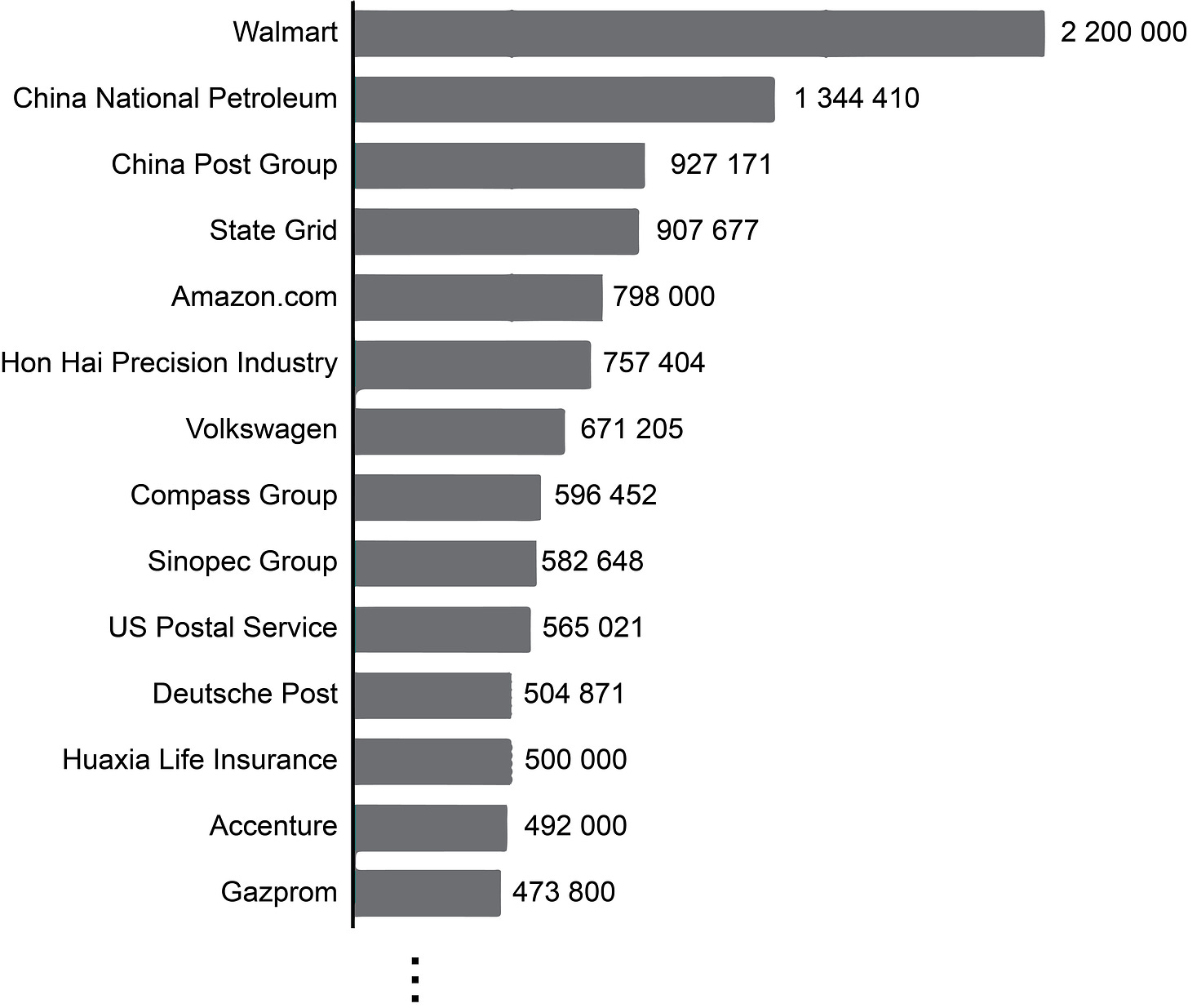
And the numbers from academia are also misleading: from experience, I can attest that the 7500 researchers of the Max Planck Society are, at most, connected by some vague set of standards and values. In actuality, the society consists of a few hundred independent research groups, each with 5 to 100 researchers. And "independence" is really important here - anything like central coordination of research would be perceived as limiting scientific freedom3 and therefore bad. Why are 10-30 researchers the de-facto limit to how large a research group can grow? Why not thousands or tens of thousands?
Some differences between academia and the Fortune 500 are apparent immediately: Academic research requires highly trained labor and is constrained by whatever the funding bodies are willing to cough up in a given academic year. Walmart needs to provide much less training to their employees and their funding is self-generated, so we can expect scaling to be much easier here.
But there are also very strong amplification forces and accumulation of resources in academia. This is the famous "Matthew effect", after the Dave Matthews band who tend to sell all the tickets in any city they play in4. The well-funded get even more funding and those with little funding get pruned out. Why doesn't this dynamic "run away"? Why isn't literally everyone a Ph.D. student of Yoshua Bengio?
Perhaps research questions are just not deep enough to have 1000s of people working on them? I don't think this is true. Most researchers have very ambitious ideas and must contend themselves to work on small portions of those questions. The Manhatten Project, the Human Genome Project, and the LHC are prominent examples of such wide-ranging projects5. I could come up with a research program that keeps 1000s of people busy. Coming up with deep research questions is not the issue.
Might we conclude that we are already at some efficient frontier most of the time? Are we squeezing out the maximal efficiency with research groups with a median size of ten people? I have a couple of reasons to believe that this is not the case and that research output could be substantially increased.
Hire more people?
#[[IAN says:] ] An army of albatrosses walks into a bar:
The albatrosses say, "We're here for the beer." The barkeep says, "Sorry, we're out of beer."
The albatrosses say, "We'll take the spirits instead." The barkeep says, "Sorry, we're out of spirits."
The albatrosses say, "We'll have a couple of those red things." The barkeep says, "Those are the glasses you drink out of."
The albatrosses say, "We'll have a dozen of those." The barkeep says, "Sorry, we're out of dozen—"
The albatrosses say, "Shut up and pour!"
Let's go by the numbers first. The typical academic chain of command is very straightforward:
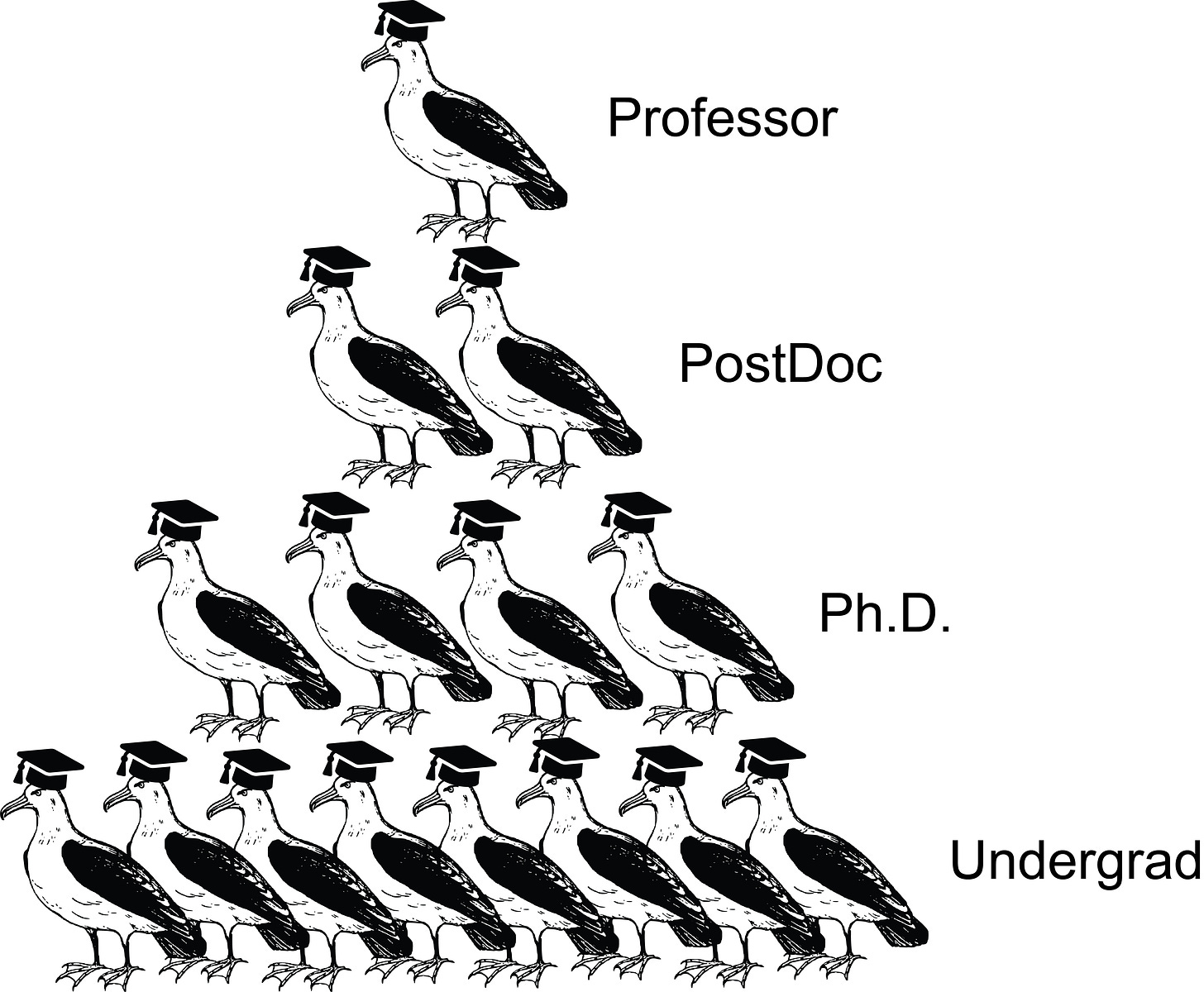
When we assume that (like in the schematic) at each level the supervision ratio is 1:2, we can easily derive the average group size:
Group size = 2^(3 + 1) - 1 = 15Successful labs manage to scale this up by increasing the number of PostDocs or by introducing senior PostDocs/Group Leaders into the mix and by pushing how many students are supervised at each level:
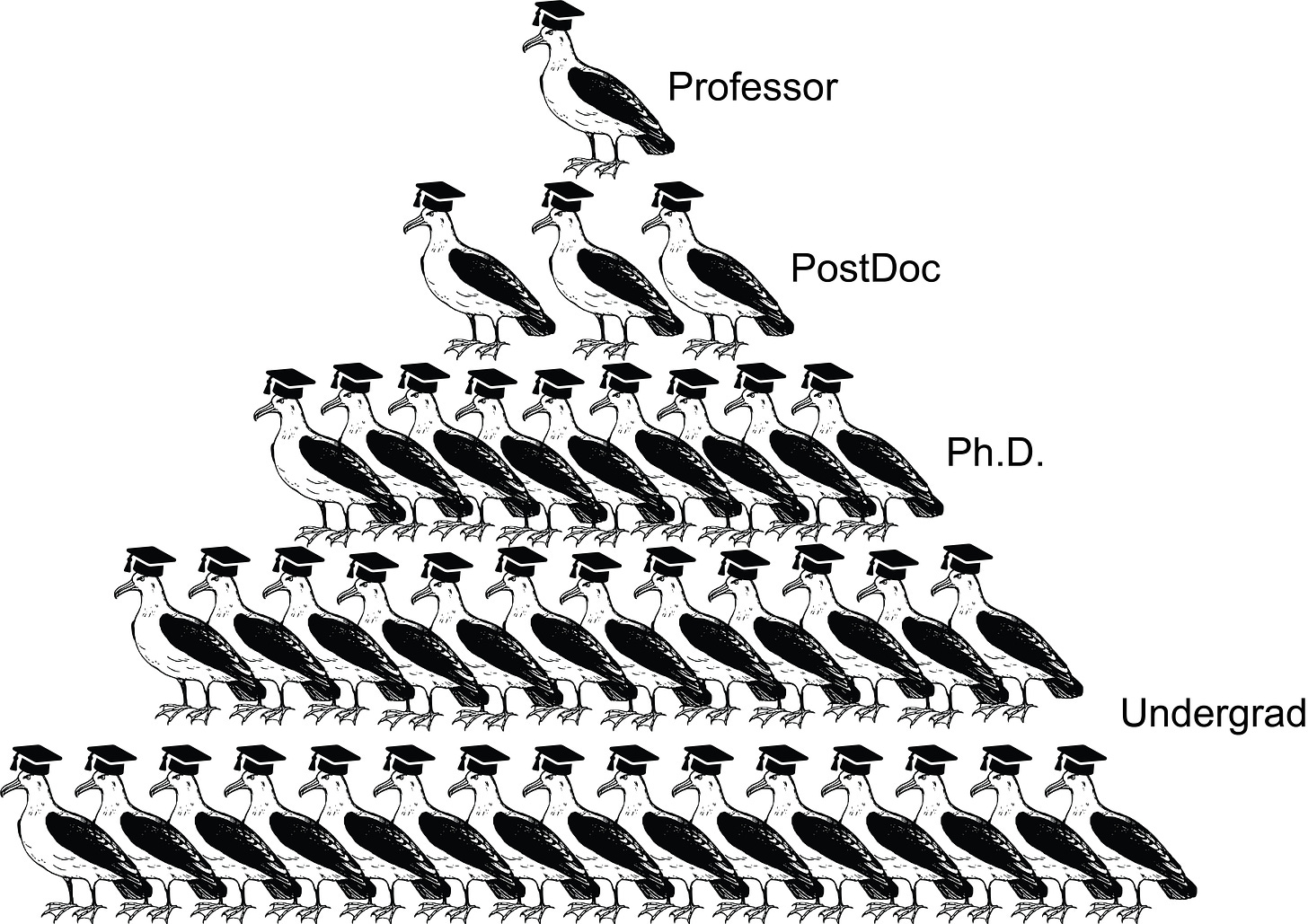
Group size = 3^4 - 1 = 80Currently, this number does not scale. Approximately one hundred researchers appears to be around the maximum of how far a traditional research group can be stretched. Why is that? There appear to be two obvious ways to increase this number: adding more levels to the hierarchy and increasing the number of researchers supervised at each level. By the power of exponents, if we can add just one more level and increase the supervision ratio to 1:5, we would jump up to
Group size = 5^5 - 1 = 3124Now we're talking. Why are we not doing that?
(Obviously, there are more factors that influence scientific output beyond group size and a strict hierarchy is not the best way to structure things6. But this objection misses the point of scaling: Having something that does scale, even if it looks stupid and over-simplified, beats something that doesn’t scale.)
Adding more levels and increasing the supervision ratio
#[[IAN says:]] By the power of exponents I call upon
Homer and his ilk; To mold us a new measure of delight,
Something so exquisite and rare; That we shall sing aloud for joy.
I am not Homer, am only a man; But I can put the words together in his power.
The natural limitation to “how deep you can make a hierarchy” is how efficiently you can propagate commands and reports up and down the chain. The natural limit to “how far you can increase the supervision ratio” is how many meetings you can squeeze into a week. This post provides a great analysis of how the FDA might actually be operating at the maximum speed possible given its insane institutional design and absurdly overloaded responsibilities:
Somewhere there are multiple leadership teams meeting who report to other leadership teams who report to the top, all of whom are trying to figure out what decisions should be made this week. And it's hard. Because if you have 10 projects ongoing and want to do a status update on all of them plus do review meetings, that's the week gone. Easily. Do this whole thing 10 times in parallel, and you could easily have an organisation of 1000s but where things take forever to move.
So the hierarchy cannot be scaled arbitrarily deep and broad, fair enough. But I have a hard time believing that academia is already maxing out its potential. Sure, every researcher at every level of the hierarchy will tell you that they are operating at the limit of what is humanly possible - but if you ask the same researcher which project management framework they are using, you get blank stares. Often, a new project is started by "just having the student read a bit" and then answering questions as they come up. If the stars align, a journal publication will pop out at the end of the process. Timelines are either non-existent or ridiculously poorly calibrated7. At the same time, we are overloading the people at the top of the hierarchy (whose time is the most valuable resource of the entire system) with all the mundane tasks, paperwork, and emails. Adapting a page from "Moloch's toolbox":
In our world, "professors" are supposed to write grants, do teaching, oversee hiring, do public outreach, attend faculty meetings, supervise, write papers and (sometimes even) do research.
Getting a secretary, lab manager, or just someone who can help with illustrations8 is somehow perceived to be an optional luxury.
The proposed solution: The answer is simple; systematize and delegate. Create (and perfect) explicit workflows for short-term student internships, undergraduate theses, Ph.D. projects, long-running lab ambitions. Have explicit timelines with regular check-ins where you see if you hit your milestones or not. Have writing guides for papers9. Set achievable, explicit goals (# of GitHub commits, # of entries in a group wiki, ...) and link career rewards to hitting these goals.
How to get there? Perhaps the solution is not as easy as "just start using agile". This post highlights the roadblocks the author ran into when trying to implement the agile framework in a traditional academic context. But the reasons for his failure can be summarized as: “traditional academia is not flexible enough to give project management frameworks a fair shot. It just doesn't compute with the academic mindset.”
I'm not satisfied with that answer. Systematizing has worked well for me in my research and I've been able to increase the number of projects I'm managing by maintaining explicit timelines (and torching projects that consistently run behind schedule). It is called the scientific method for a reason. There are great workflows and frameworks that can be applied in almost arbitrary contexts. And the tools that support researchers are becoming better and more numerous every month (see IAN and the like). The time is ripe for truly ambitious scaling of research and new institutions like New Science have the potential to be the catalyzer for much of this progress.
Possibility of low hanging fruit and lack of objective metrics
#[[IAN says:]] Here is a classic proverb about low-hanging fruit: Eat the seeds you planted, not the fruit that ripened.

What would it mean for academia to be "efficient"? I like this definition from economics illustrated by the joke about the economist who won’t pick up the 20$ bill lying on a busy street because "if it was real, somebody else would have already picked it up". In academia, this translates to the statement "there is no low-hanging fruit": If you think you made an exciting new discovery after investing only little effort, you should be wary. Most likely, you are either wrong or somebody else already made this discovery and published it in the 1960s.
Physics is one subfield of science that appears to be "efficient" in this sense. If you think you have built a Perpetuum mobile, you are probably wrong. The same goes for mathematics, where amateur "proofs" of ancient theorems always10 turn out to be wrong. Famously, Edmund Landau received so many incorrect amateur proofs that he prepared a form letter saying "Dear Sir or Madam: Your proof of Fermat's Last Theorem has been received. The first mistake is on page _ line _ ." so that he'd only have to fill in the page and the line.
But it is wrong to conclude that every subfield of science is efficient. In 1880, observing a squirrel swimming across a river gave you a good shot at getting published in Nature. "The developmental psychology of linguistics could've been discovered in the eighteenth century, in principle, but no one had even thought to look until the twentieth." Beyond a few "funny" (by academic standards) ridiculously short journal papers, there are also extremely short Ph.D. theses from excellent researchers. And when physics was still "young", people like Newton or Euler singlehandedly made all the exciting discoveries.
Physics and mathematics are not young disciplines anymore, but Neuroscience, Cognitive Science, and Machine Learning are. Could it be that there are tons of "low-hanging fruit" that nobody is able to pick? I'm not the first to argue that academia might be inefficient in this sense - the gist here is the mismatch between "what funders value" and "what would be great for humanity". All the low-hanging fruit in the quadrant "not valued by funders, but still great for humanity" will not get picked.
Beyond this general argument, we are lacking objective metrics to evaluate what constitutes a "great scientific result". As a substitute, a lot of scientists use the proxy "time spent on a project" to evaluate the "quality of a project". This has been internalized to the point where I have seen many colleagues discarding the straightforward and fast solution (i.e. the low-hanging fruit) in favor of a more complicated and time-intense solution. Again, I'm not the first to observe academia's unhealthy relationship with simple solutions: Andrew Ng received a surprising amount of pushback when suggesting that GPUs could be used in computer vision because this was somehow perceived as cheating.
Once objective metrics are adopted (like in protein folding), great scientific results will be acknowledged even when they come from "newcomers" and the results are derived in a much shorter time than the "time=quality" proxy would suggest.
The proposed solution: If we accept that better metrics are (part of) what is missing for scaling science, there is one prominent candidate that is the "golden boy" of the rationality community: prediction markets.
The prediction market is a market where people can trade contracts that pay based on the outcomes of unknown future events. The market prices generated from these contracts can be understood as a kind of collective prediction among market participants. These prices are based on the individual expectations and willingness of investors to put their money on the line for those expectations.
In my ideal world, we would establish prediction markets for everything. This would solve so many problems:
First and foremost, we would get a computerized representation of expert knowledge/uncertainty about the state of the art in all areas of science. This opens the door to quantitative reasoning about so many things.
It would provide a numerical estimate of how "difficult" a question was perceived to be before it was answered. For example, Metaculus asks "By 2030, will C. elegans be uploaded to the satisfaction of top computational neuroscientists?" The community converged on (through, at the time of writing, 159 predictions) a 40% probability. If a research team manages to upload C. elegans by 2025, that would be a huge deal and the scientific community would have a harder time trivializing it.
Academics specializing in an esoteric topic currently might struggle to find a job, even though their expertise is certainly valuable. It's just that no single company needs a monopoly on that knowledge as much as it wants to not pay an additional salary. A scientific prediction market would allow the Ph.D. with niche expertise to systematically beat the market on a few questions and earn a living wage that way - while simultaneously increasing the power of the prediction market.
It is well documented that markets are great at predicting whether a study will replicate or not. By leaning into prediction markets, we might be able to get out of the current horrible system where the quality of a study is a rough function of the impact factor of the journal, the prestige of the group, and the visual appeal of the figures; and instead, evaluate a study based on the solidity of the results.
How to get there? This is a coordination problem and I have little hope that all of academia (part of which really likes the current system of subjective metrics) will adopt prediction markets because of this post (although they totally should).
However, not all of academia has to switch. While "glory" and "funding" for picking low-hanging fruit might only follow once the larger part of academia adopts better metrics, you still get to keep the low-hanging fruit regardless. If only one discipline (Machine Learning, Cognitive Science?) or even just one sub-community (EAs? Rationalists?) can be convinced to adopt objective metrics, they can already reap the benefits.
Setting up an academic prediction market that is technically well-done and fun to use could do a lot of good. Perhaps Metaculus is already exactly that platform11. Alternatively, one could start a new scientific journal that has a prediction market for replication probability embedded for each paper? To reach a critical mass of scientific submissions, the journal could focus on publishing undergraduate or master theses in the beginning (which can be of surprisingly high quality). Finally, every academic reading this can do their part by calling their colleagues out on their bad predictions. This ties in with the previous section's point about calibrated timelines.
Better tools, better science
Please don’t think that I was intentionally burying the lede. I do believe that
- systematizing scientific work (collecting and refining explicit workflows)
- improving metrics of scientific progress (through f.e. prediction markets)
would be genuinely awesome things for academia at large. If I ever get to have my own lab, those two components will be high on my list of priorities. But it also turns out that those two components would go a long way towards automating research. I’m thinking a lot about how I could replace my students with Robo Researchers12:
… Okay, that came out wrong. What I actually mean is that I’m thinking a lot about how I could augment my research with Robo Researchers:
My motivation for thinking about Robo Researchers is exactly the same as the motivation for accepting to supervise students in the first place: A day only has 24 hours and there is so much to do and it’s awesome to have someone help you. And let’s face it: a lot of the “stuff-that-needs-doing” is just grunt work. A typical task for a student of mine is “Can you run those simulations again but with different values of θ and put the results on slides?” or “Can you read up on the effect of the Fragile X mutation on SST interneurons in early development and write me a brief summary?“. If we could get a Robo Researcher to assist with that, that would be a big win for everyone involved. And with a software suite composed of something like Codex, a fine-tuned language model, and Ought’s Elicit I think I am not too far away from making that a reality.
Conclusion
While systematizing and introducing better metrics promise marginal improvements to research output, automation has the potential to be transformative. A lot has been said on the question of whether scientific progress is slowing down, but an equal amount has been said on how technology accelerates everything it touches. And it does not take a huge stretch of the imagination to see this trend reach research in due time. The consequences are hard to forecast and it’s a difficult question of whether it’s a desirable thing or not. Does “more research = more good” actually hold if we push to the extremes?13 I’m on the fence about this.
Different point. Grace et al. performed an influential survey among machine learning experts about their timelines for when certain tasks can be accomplished by AI at the same level as humans:
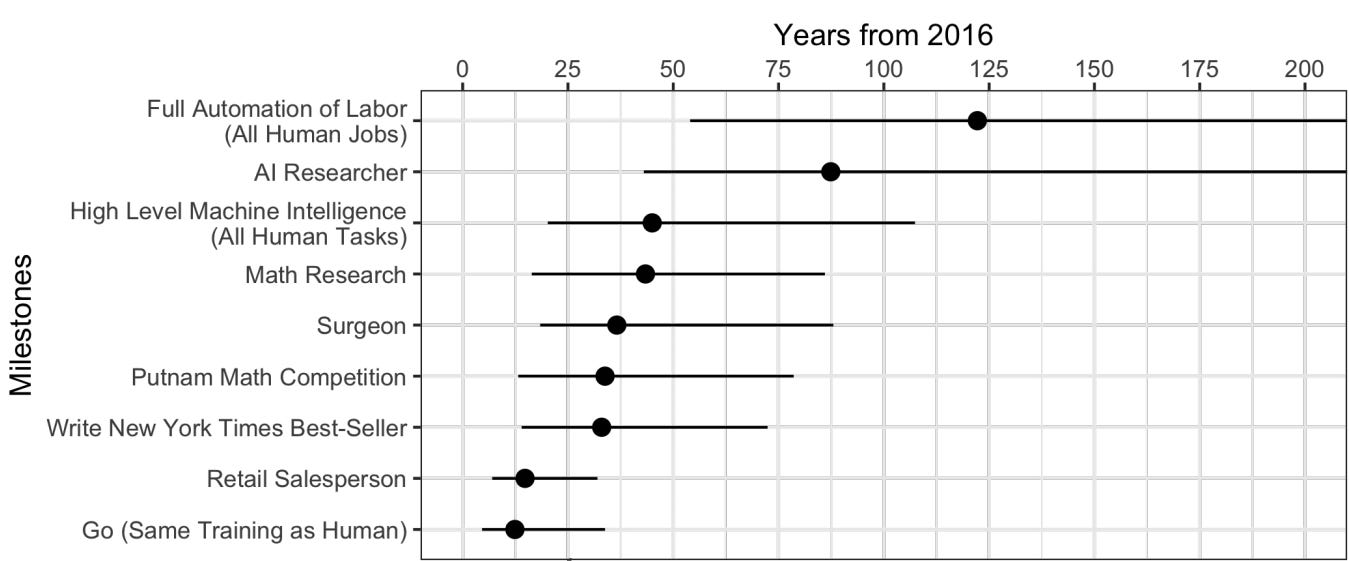
But I think this provides a false sense of job security for researchers. Here are some reasons why it might take a lot less than 45 years before (f.e.) a math researcher starts feeling the impact of AI:
AI doesn’t have to reach human-level for being useful and impactful in academic research.
The amount of grunt-work in academia is underappreciated and automating it away is very much in reach.
A good bit of academia does not require performing experiments in the physical world but resembles software engineering - which is on the verge of becoming more automated.
AI researchers have no idea about the typical workflows of a surgeon or of publishing an NYT bestseller. They do have a lot of insight into the typical workflow of a researcher.
I have a hard time figuring out what to make of this. One rather obvious conclusion for me is that I should not expect the near future in academia to look a lot like the last ten years. Putting myself in a position where I have the tools to pick low-hanging fruit as soon as it becomes feasible also sounds smart. Making sure that not everything goes terribly wrong? Not so sure how to tackle that one yet. Stay tuned.
Once again, big “thank you” to Nadia Mir-Montazeri for extremely useful feedback on this post!
Footnotes:
1 And I will voice my concerns loudly on this Substack in due time.
2 Although some say much less, the exact number is disputed.
3 The situation at the CAS is probably different, see f.e. the Pioneer Initiative. If anybody has more insight on how much research "on the ground" is centrally coordinated, I'd be interested to hear about it!
4 Okay, okay. “For to every one who has will more be given, and he will have abundance; but from him who has not, even what he has will be taken away.” — Matthew 25:29, RSV.
5 And their respective successes and failures are highly instructive.
6 This extremely thorough and well-written EA Forum post seeks to identify the key factors that make some research teams more effective than others.
7 Timelines being poorly calibrated is of course the standard everywhere. But academics should really know better, or at least start learning not to trust their gut feeling at some point.
8 Guess where I learned to make pretty illustrations of albatrosses?
9 Which are not passed on in ancient scrolls .docx files from senior PostDocs to PhDs, but instead are stored in a central repository.
10 Exceptions prove the rule.
11 Although "real" financial incentives (rather than internet points) are obviously necessary to make this a viable source of income for experts.
12 If you’re reading this: no offense, y’all are great.
13 Once I’ve thought about it more this will be another post.
Interesting points. Anecdotally, I also think that the research output of most PIs that I got to know better was significantly constrained by busywork that could be outsourced relatively easily.
I'm spontaneously doubtful that a realistic version of a scientific prediction market will provide a living wage this way. E.g. with the most liquid polymarket question, currently at .75c, you can at maximum expect a profit of 5.000$ if you're sure the event will happen and wager 10.000$.
Re Setting up an academic prediction markets: Eva Vivalt has set up a prediction platform for social science studies some time ago that might be interesting to look into: https://socialscienceprediction.org/
Thank you very much for sharing, I didn't know that platform before! Looks like a great initiative and the science article is also very inspired. The failure mode I see is that they might be aiming too broad - realistically for this to take off you might want to start with a small group of very devoted users who can also benefit from the effort they invest? But finding that group poses a different set of problems, of course.
Regarding the "living wage" argument - thank you for calling me out on that, I crossed the line into science fiction there.
Just found an article by Robin Hanson from 1990 on this topic: http://mason.gmu.edu/~rhanson/gamble.html I didn't realize that the idea had been around for that long!