The following is my considered evaluation of the Foundational Research Institute, circa July 2017. I discuss its goal, where I foresee things going wrong with how it defines suffering, and what it could do to avoid these problems.
TL;DR version: functionalism ("consciousness is the sum-total of the functional properties of our brains") sounds a lot better than it actually turns out to be in practice. In particular, functionalism makes it impossible to define ethics & suffering in a way that can mediate disagreements.
I. What is the Foundational Research Institute?
The Foundational Research Institute (FRI) is a Berlin-based group that "conducts research on how to best reduce the suffering of sentient beings in the near and far future." Executive Director Max Daniel introduced them at EA Global Boston as “the only EA organization which at an organizational level has the mission of focusing on reducing s-risk.” S-risks are, according to Daniel, “risks where an adverse outcome would bring about suffering on an astronomical scale, vastly exceeding all suffering that has existed on Earth so far.”
Essentially, FRI wants to become the research arm of suffering-focused ethics, and help prevent artificial general intelligence (AGI) failure-modes which might produce suffering on a cosmic scale.
What I like about FRI:
While I have serious qualms about FRI’s research framework, I think the people behind FRI deserve a lot of credit- they seem to be serious people, working hard to build something good. In particular, I want to give them a shoutout for three things:
-
First, FRI takes suffering seriously, and I think that’s important. When times are good, we tend to forget how tongue-chewingly horrific suffering can be. S-risks seem particularly horrifying.
-
Second, FRI isn’t afraid of being weird. FRI has been working on s-risk research for a few years now, and if people are starting to come around to the idea that s-risks are worth thinking about, much of the credit goes to FRI.
-
Third, I have great personal respect for Brian Tomasik, one of FRI’s co-founders. I’ve found him highly thoughtful, generous in debates, and unfailingly principled. In particular, he’s always willing to bite the bullet and work ideas out to their logical end, even if it involves repugnant conclusions.
What is FRI’s research framework?
FRI believes in analytic functionalism, or what David Chalmers calls “Type-A materialism”. Essentially, what this means is there’s no ’theoretical essence’ to consciousness; rather, consciousness is the sum-total of the functional properties of our brains. Since ‘functional properties’ are rather vague, this means consciousness itself is rather vague, in the same way words like “life,” “justice,” and “virtue” are messy and vague.
Brian suggests that this vagueness means there’s an inherently subjective, perhaps arbitrary element to how we define consciousness:
Analytic functionalism looks for functional processes in the brain that roughly capture what we mean by words like "awareness", "happy", etc., in a similar way as a biologist may look for precise properties of replicators that roughly capture what we mean by "life". Just as there can be room for fuzziness about where exactly to draw the boundaries around "life", different analytic functionalists may have different opinions about where to define the boundaries of "consciousness" and other mental states. This is why consciousness is "up to us to define". There's no hard problem of consciousness for the same reason there's no hard problem of life: consciousness is just a high-level word that we use to refer to lots of detailed processes, and it doesn't mean anything in addition to those processes.
Finally, Brian argues that the phenomenology of consciousness is identical with the phenomenology of computation:
I know that I'm conscious. I also know, from neuroscience combined with Occam's razor, that my consciousness consists only of material operations in my brain -- probably mostly patterns of neuronal firing that help process inputs, compute intermediate ideas, and produce behavioral outputs. Thus, I can see that consciousness is just the first-person view of certain kinds of computations -- as Eliezer Yudkowsky puts it, "How An Algorithm Feels From Inside". Consciousness is not something separate from or epiphenomenal to these computations. It is these computations, just from their own perspective of trying to think about themselves.
In other words, consciousness is what minds compute. Consciousness is the collection of input operations, intermediate processing, and output behaviors that an entity performs.
And if consciousness is all these things, so too is suffering. Which means suffering is computational, yet also inherently fuzzy, and at least a bit arbitrary; a leaky high-level reification impossible to speak about accurately, since there’s no formal, objective “ground truth”.
II. Why do I worry about FRI’s research framework?
In short, I think FRI has a worthy goal and good people, but its metaphysics actively prevent making progress toward that goal. The following describes why I think that, drawing heavily on Brian’s writings (of FRI’s researchers, Brian seems the most focused on metaphysics):
Note: FRI is not the only EA organization which holds functionalist views on consciousness; much of the following critique would also apply to e.g. MIRI, FHI, and OpenPhil. I focus on FRI because (1) Brian’s writings on consciousness & functionalism have been hugely influential in the community, and are clear enough *to* criticize; (2) the fact that FRI is particularly clear about what it cares about- suffering- allows a particularly clear critique about what problems it will run into with functionalism; (3) I believe FRI is at the forefront of an important cause area which has not crystallized yet, and I think it’s critically important to get these objections bouncing around this subcommunity.
Objection 1: Motte-and-bailey
Brian: “Consciousness is not a thing which exists ‘out there’ or even a separate property of matter; it's a definitional category into which we classify minds. ‘Is this digital mind really conscious?’ is analogous to ‘Is a rock that people use to eat on really a table?’ [However,] That consciousness is a cluster in thingspace rather than a concrete property of the world does not make reducing suffering less important.”
The FRI model seems to imply that suffering is ineffable enough such that we can't have an objective definition, yet sufficiently effable that we can coherently talk and care about it. This attempt to have it both ways seems contradictory, or at least in deep tension.
Indeed, I’d argue that the degree to which you can care about something is proportional to the degree to which you can define it objectively. E.g., If I say that “gnireffus” is literally the most terrible thing in the cosmos, that we should spread gnireffus-focused ethics, and that minimizing g-risks (far-future scenarios which involve large amounts of gnireffus) is a moral imperative, but also that what is and what isn’t gnireffus is rather subjective with no privileged definition, and it’s impossible to objectively tell if a physical system exhibits gnireffus, you might raise any number of objections. This is not an exact metaphor for FRI’s position, but I worry that FRI’s work leans on the intuition that suffering is real and we can speak coherently about it, to a degree greater than its metaphysics formally allow.
Max Daniel (personal communication) suggests that we’re comfortable with a degree of ineffability in other contexts; “Brian claims that the concept of suffering shares the allegedly problematic properties with the concept of a table. But it seems a stretch to say that the alleged tension is problematic when talking about tables. So why would it be problematic when talking about suffering?” However, if we take the anti-realist view that suffering is ‘merely’ a node in the network of language, we have to live with the consequences of this: that ‘suffering’ will lose meaning as we take it away from the network in which it’s embedded (Wittgenstein). But FRI wants to do exactly this, to speak about suffering in the context of AGIs, simulated brains, even video game characters.
We can be anti-realists about suffering (suffering-is-a-node-in-the-network-of-language), or we can argue that we can talk coherently about suffering in novel contexts (AGIs, mind crime, aliens, and so on), but it seems inherently troublesome to claim we can do both at the same time.
Objection 2: Intuition duels
Two people can agree on FRI’s position that there is no objective fact of the matter about what suffering is (no privileged definition), but this also means they have no way of coming to any consensus on the object-level question of whether something can suffer. This isn’t just an academic point: Brian has written extensively about how he believes non-human animals can and do suffer extensively, whereas Yudkowsky (who holds computationalist views, like Brian) has written about how he’s confident that animals are not conscious and cannot suffer, due to their lack of higher-order reasoning.
And if functionalism is having trouble adjudicating the easy cases of suffering--whether monkeys can suffer, or whether dogs can— it doesn’t have a sliver of a chance at dealing with the upcoming hard cases of suffering: whether a given AGI is suffering, or engaging in mind crime; whether a whole-brain emulation (WBE) or synthetic organism or emergent intelligence that doesn’t have the capacity to tell us how it feels (or that we don’t have the capacity to understand) is suffering; if any aliens that we meet in the future can suffer; whether changing the internal architecture of our qualia reports means we’re also changing our qualia; and so on.
In short, FRI’s theory of consciousness isn’t actually a theory of consciousness at all, since it doesn’t do the thing we need a theory of consciousness to do: adjudicate disagreements in a principled way. Instead, it gives up any claim on the sorts of objective facts which could in principle adjudicate disagreements.
This is a source of friction in EA today, but it’s mitigated by the sense that
(1) The EA pie is growing, so it’s better to ignore disagreements than pick fights;
(2) Disagreements over the definition of suffering don’t really matter yet, since we haven’t gotten into the business of making morally-relevant synthetic beings (that we know of) that might be unable to vocalize their suffering.
If the perception of one or both of these conditions change, the lack of some disagreement-adjudicating theory of suffering will matter quite a lot.
Objection 3: Convergence requires common truth
Mike: “[W]hat makes one definition of consciousness better than another? How should we evaluate them?”
Brian: “Consilience among our feelings of empathy, principles of non-discrimination, understandings of cognitive science, etc. It's similar to the question of what makes one definition of justice or virtue better than another.”
Brian is hoping that affective neuroscience will slowly converge to accurate views on suffering as more and better data about sentience and pain accumulates. But convergence to truth implies something (objective) driving the convergence- in this way, Brian’s framework still seems to require an objective truth of the matter, even though he disclaims most of the benefits of assuming this.
Objection 4: Assuming that consciousness is a reification produces more confusion, not less
Brian: “Consciousness is not a reified thing; it's not a physical property of the universe that just exists intrinsically. Rather, instances of consciousness are algorithms that are implemented in specific steps. … Consciousness involves specific things that brains do.”
Brian argues that we treat conscious/phenomenology as more 'real' than it is. Traditionally, whenever we’ve discovered something is a leaky reification and shouldn’t be treated as ‘too real’, we’ve been able to break it down into more coherent constituent pieces we can treat as real. Life, for instance, wasn’t due to élan vital but a bundle of self-organizing properties & dynamics which generally co-occur. But carrying out this “de-reification” process on consciousness-- enumerating its coherent constituent pieces-- has proven difficult, especially if we want to preserve some way to speak cogently about suffering.
Speaking for myself, the more I stared into the depths of functionalism, the less certain everything about moral value became-- and arguably, I see the same trajectory in Brian’s work and Luke Muehlhauser’s report. Their model uncertainty has seemingly become larger as they’ve looked into techniques for how to “de-reify” consciousness while preserving some flavor of moral value, not smaller. Brian and Luke seem to interpret this as evidence that moral value is intractably complicated, but this is also consistent with consciousness not being a reification, and instead being a real thing. Trying to “de-reify” something that’s not a reification will produce deep confusion, just as surely trying to treat a reification as ‘more real’ than it actually is will.
Edsger W. Dijkstra famously noted that “The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.” And so if our ways of talking about moral value fail to ‘carve reality at the joints’- then by all means let’s build better ones, rather than giving up on precision.
Objection 5: The Hard Problem of Consciousness is a red herring
Brian spends a lot of time discussing Chalmers’ “Hard Problem of Consciousness”, i.e. the question of why we’re subjectively conscious, and seems to base at least part of his conclusion on not finding this question compelling— he suggests “There's no hard problem of consciousness for the same reason there's no hard problem of life: consciousness is just a high-level word that we use to refer to lots of detailed processes, and it doesn't mean anything in addition to those processes.” I.e., no ‘why’ is necessary; when we take consciousness and subtract out the details of the brain, we’re left with an empty set.
But I think the “Hard Problem” isn’t helpful as a contrastive centerpiece, since it’s unclear what the problem is, and whether it’s analytic or empirical, a statement about cognition or about physics. At the Qualia Research Institute (QRI), we don’t talk much about the Hard Problem; instead, we talk about Qualia Formalism, or the idea that any phenomenological state can be crisply and precisely represented by some mathematical object. I suspect this would be a better foil for Brian’s work than the Hard Problem.
Objection 6: Mapping to reality
Brian argues that consciousness should be defined at the functional/computational level: given a Turing machine, or neural network, the right ‘code’ will produce consciousness. But the problem is that this doesn’t lead to a theory which can ‘compile’ to physics. Consider the following:
Imagine you have a bag of popcorn. Now shake it. There will exist a certain ad-hoc interpretation of bag-of-popcorn-as-computational-system where you just simulated someone getting tortured, and other interpretations that don't imply that. Did you torture anyone? If you're a computationalist, no clear answer exists- you both did, and did not, torture someone. This sounds like a ridiculous edge-case that would never come up in real life, but in reality it comes up all the time, since there is no principled way to *objectively derive* what computation(s) any physical system is performing.
I don’t think this is an outlandish view of functionalism; Brian suggests much the same in How to Interpret a Physical System as a Mind: “Physicalist views that directly map from physics to moral value are relatively simple to understand. Functionalism is more complex, because it maps from physics to computations to moral value. Moreover, while physics is real and objective, computations are fictional and ‘observer-relative’ (to use John Searle's terminology). There's no objective meaning to ‘the computation that this physical system is implementing’ (unless you're referring to the specific equations of physics that the system is playing out).”
Gordon McCabe (McCabe 2004) provides a more formal argument to this effect— that precisely mapping between physical processes and (Turing-level) computational processes is inherently impossible— in the context of simulations. First, McCabe notes that:
[T]here is a one-[to-]many correspondence between the logical states [of a computer] and the exact electronic states of computer memory. Although there are bijective mappings between numbers and the logical states of computer memory, there are no bijective mappings between numbers and the exact electronic states of memory.
This lack of an exact bijective mapping means that subjective interpretation necessarily creeps in, and so a computational simulation of a physical system can’t be ‘about’ that system in any rigorous way:
In a computer simulation, the values of the physical quantities possessed by the simulated system are represented by the combined states of multiple bits in computer memory. However, the combined states of multiple bits in computer memory only represent numbers because they are deemed to do so under a numeric interpretation. There are many different interpretations of the combined states of multiple bits in computer memory. If the numbers represented by a digital computer are interpretation-dependent, they cannot be objective physical properties. Hence, there can be no objective relationship between the changing pattern of multiple bit-states in computer memory, and the changing pattern of quantity-values of a simulated physical system.
McCabe concludes that, metaphysically speaking,
A digital computer simulation of a physical system cannot exist as, (does not possess the properties and relationships of), anything else other than a physical process occurring upon the components of a computer. In the contemporary case of an electronic digital computer, a simulation cannot exist as anything else other than an electronic physical process occurring upon the components and circuitry of a computer.
Where does this leave ethics? In Flavors of Computation Are Flavors of Consciousness, Brian notes that “In some sense all I've proposed here is to think of different flavors of computation as being various flavors of consciousness. But this still leaves the question: Which flavors of computation matter most? Clearly whatever computations happen when a person is in pain are vastly more important than what's happening in a brain on a lazy afternoon. How can we capture that difference?”
But if Brian grants the former point- that "There's no objective meaning to ‘the computation that this physical system is implementing’”- then this latter task of figuring out “which flavors of computation matter most” is provably impossible. There will always be multiple computational (and thus ethical) interpretations of a physical system, with no way to figure out what’s “really” happening. No way to figure out if something is suffering or not. No consilience; not now, not ever.
Note: despite apparently granting the point above, Brian also remarks that:
I should add a note on terminology: All computations occur within physics, so any computation is a physical process. Conversely, any physical process proceeds from input conditions to output conditions in a regular manner and so is a computation. Hence, the set of computations equals the set of physical processes, and where I say "computations” in this piece, one could just as well substitute "physical processes" instead.
This seems to be (1) incorrect, for the reasons I give above, or (2) taking substantial poetic license with these terms, or (3) referring to hypercomputation (which might be able to salvage the metaphor, but would invalidate many of FRI’s conclusions dealing with the computability of suffering on conventional hardware).
This objection may seem esoteric or pedantic, but I think it’s important, and that it ripples through FRI’s theoretical framework with disastrous effects.
Objection 7: FRI doesn't fully bite the bullet on computationalism
Brian suggests that “flavors of computation are flavors of consciousness” and that some computations ‘code’ for suffering. But if we do in fact bite the bullet on this metaphor and place suffering within the realm of computational theory, we need to think in “near mode” and accept all the paradoxes that brings. Scott Aaronson, a noted expert on quantum computing, raises the following objections to functionalism:
I’m guessing that many people in this room side with Dennett, and (not coincidentally, I’d say) also with Everett. I certainly have sympathies in that direction too. In fact, I spent seven or eight years of my life as a Dennett/Everett hardcore believer. But, while I don’t want to talk anyone out of the Dennett/Everett view, I’d like to take you on a tour of what I see as some of the extremely interesting questions that that view leaves unanswered. I’m not talking about “deep questions of meaning,” but about something much more straightforward: what exactly does a computational process have to do to qualify as “conscious”?
…
There’s this old chestnut, what if each person on earth simulated one neuron of your brain, by passing pieces of paper around. It took them several years just to simulate a single second of your thought processes. Would that bring your subjectivity into being? Would you accept it as a replacement for your current body? If so, then what if your brain were simulated, not neuron-by-neuron, but by a gigantic lookup table? That is, what if there were a huge database, much larger than the observable universe (but let’s not worry about that), that hardwired what your brain’s response was to every sequence of stimuli that your sense-organs could possibly receive. Would that bring about your consciousness? Let’s keep pushing: if it would, would it make a difference if anyone actually consulted the lookup table? Why can’t it bring about your consciousness just by sitting there doing nothing?
To these standard thought experiments, we can add more. Let’s suppose that, purely for error-correction purposes, the computer that’s simulating your brain runs the code three times, and takes the majority vote of the outcomes. Would that bring three “copies” of your consciousness into being? Does it make a difference if the three copies are widely separated in space or time—say, on different planets, or in different centuries? Is it possible that the massive redundancy taking place in your brain right now is bringing multiple copies of you into being?
...
Maybe my favorite thought experiment along these lines was invented by my former student Andy Drucker. In the past five years, there’s been a revolution in theoretical cryptography, around something called Fully Homomorphic Encryption (FHE), which was first discovered by Craig Gentry. What FHE lets you do is to perform arbitrary computations on encrypted data, without ever decrypting the data at any point. So, to someone with the decryption key, you could be proving theorems, simulating planetary motions, etc. But to someone without the key, it looks for all the world like you’re just shuffling random strings and producing other random strings as output.
You can probably see where this is going. What if we homomorphically encrypted a simulation of your brain? And what if we hid the only copy of the decryption key, let’s say in another galaxy? Would this computation—which looks to anyone in our galaxy like a reshuffling of gobbledygook—be silently producing your consciousness?
When we consider the possibility of a conscious quantum computer, in some sense we inherit all the previous puzzles about conscious classical computers, but then also add a few new ones. So, let’s say I run a quantum subroutine that simulates your brain, by applying some unitary transformation U. But then, of course, I want to “uncompute” to get rid of garbage (and thereby enable interference between different branches), so I apply U-1. Question: when I apply U-1, does your simulated brain experience the same thoughts and feelings a second time? Is the second experience “the same as” the first, or does it differ somehow, by virtue of being reversed in time? Or, since U-1U is just a convoluted implementation of the identity function, are there no experiences at all here?
Here’s a better one: many of you have heard of the Vaidman bomb. This is a famous thought experiment in quantum mechanics where there’s a package, and we’d like to “query” it to find out whether it contains a bomb—but if we query it and there is a bomb, it will explode, killing everyone in the room. What’s the solution? Well, suppose we could go into a superposition of querying the bomb and not querying it, with only ε amplitude on querying the bomb, and √(1-ε2) amplitude on not querying it. And suppose we repeat this over and over—each time, moving ε amplitude onto the “query the bomb” state if there’s no bomb there, but moving ε2 probability onto the “query the bomb” state if there is a bomb (since the explosion decoheres the superposition). Then after 1/ε repetitions, we’ll have order 1 probability of being in the “query the bomb” state if there’s no bomb. By contrast, if there is a bomb, then the total probability we’ve ever entered that state is (1/ε)×ε2 = ε. So, either way, we learn whether there’s a bomb, and the probability that we set the bomb off can be made arbitrarily small. (Incidentally, this is extremely closely related to how Grover’s algorithm works.)
OK, now how about the Vaidman brain? We’ve got a quantum subroutine simulating your brain, and we want to ask it a yes-or-no question. We do so by querying that subroutine with ε amplitude 1/ε times, in such a way that if your answer is “yes,” then we’ve only ever activated the subroutine with total probability ε. Yet you still manage to communicate your “yes” answer to the outside world. So, should we say that you were conscious only in the ε fraction of the wavefunction where the simulation happened, or that the entire system was conscious? (The answer could matter a lot for anthropic purposes.)
To sum up: Brian’s notion that consciousness is the same as computation raises more issues than it solves; in particular, the possibility that if suffering is computable, it may also be uncomputable/reversible, would suggest s-risks aren’t as serious as FRI treats them.
Objection 8: Dangerous combination
Three themes which seem to permeate FRI’s research are:
(1) Suffering is the thing that is bad.
(2) It’s critically important to eliminate badness from the universe.
(3) Suffering is impossible to define objectively, and so we each must define what suffering means for ourselves.
Taken individually, each of these seems reasonable. Pick two, and you’re still okay. Pick all three, though, and you get A Fully General Justification For Anything, based on what is ultimately a subjective/aesthetic call.
Much can be said in FRI’s defense here, and it’s unfair to single them out as risky: in my experience they’ve always brought a very thoughtful, measured, cooperative approach to the table. I would just note that ideas are powerful, and I think theme (3) is especially pernicious if incorrect.
III. QRI’s alternative
Analytic functionalism is essentially a negative hypothesis about consciousness: it's the argument that there's no order to be found, no rigor to be had. It obscures this with talk of "function", which is a red herring it not only doesn't define, but admits is undefinable. It doesn't make any positive assertion. Functionalism is skepticism- nothing more, nothing less.
But is it right?
Ultimately, I think these a priori arguments are much like people in the middle ages arguing whether one could ever formalize a Proper System of Alchemy. Such arguments may in many cases hold water, but it's often difficult to tell good arguments apart from arguments where we're just cleverly fooling ourselves. In retrospect, the best way to *prove* systematized alchemy was possible was to just go out and *do* it, and invent Chemistry. That's how I see what we're doing at QRI with Qualia Formalism: we’re assuming it’s possible to build stuff, and we’re working on building the object-level stuff.
What we’ve built with QRI’s framework
Note: this is a brief, surface-level tour of our research; it will probably be confusing for readers who haven't dug into our stuff before. Consider this a down-payment on a more substantial introduction.
My most notable work is Principia Qualia, in which I lay out my meta-framework for consciousness (a flavor of dual-aspect monism, with a focus on Qualia Formalism) and put forth the Symmetry Theory of Valence (STV). Essentially, the STV is an argument that much of the apparent complexity of emotional valence is evolutionarily contingent, and if we consider a mathematical object isomorphic to a phenomenological experience, the mathematical property which corresponds to how pleasant it is to be that experience is the object’s symmetry. This implies a bunch of testable predictions and reinterpretations of things like what ‘pleasure centers’ do (Section XI; Section XII). Building on this, I offer the Symmetry Theory of Homeostatic Regulation, which suggests understanding the structure of qualia will translate into knowledge about the structure of human intelligence, and I briefly touch on the idea of Neuroacoustics.
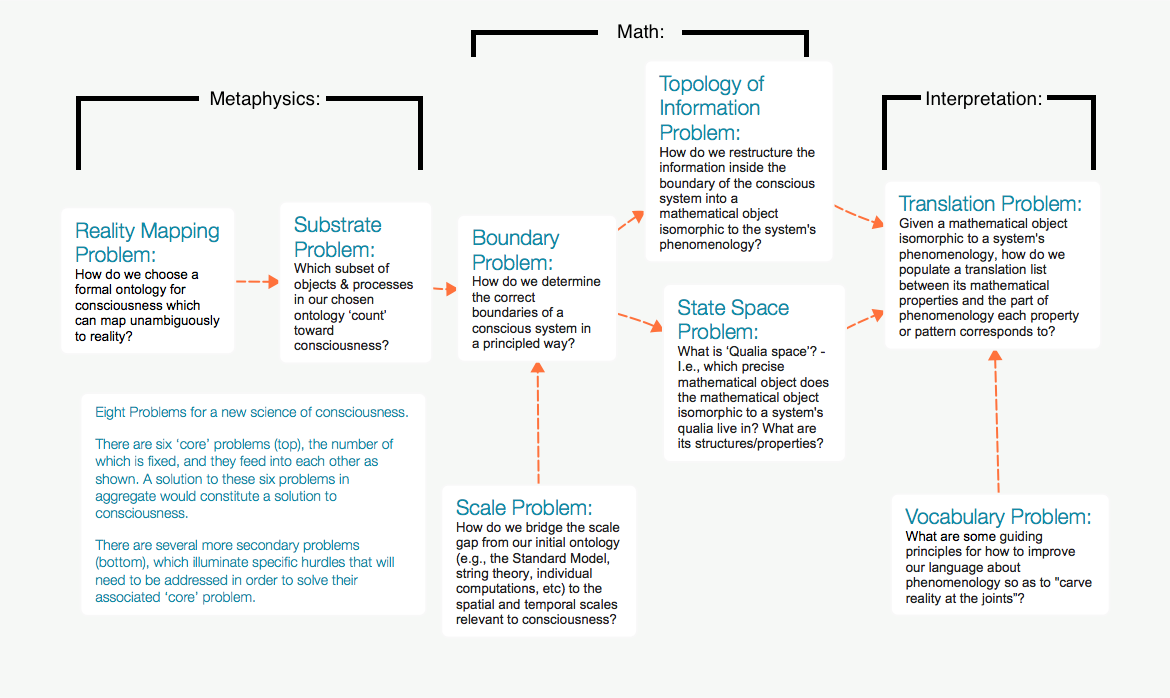{kind=link}
Likewise, my colleague Andrés Gomez Emilsson has written about the likely mathematics of phenomenology, including The Hyperbolic Geometry of DMT Experiences, Tyranny of the Intentional Object, and Algorithmic Reduction of Psychedelic States. If I had to suggest one thing to read in all of these links, though, it would be the transcript of his recent talk on Quantifying Bliss, which lays out the world’s first method to objectively measure valence from first principles (via fMRI) using Selen Atasoy’s Connectome Harmonics framework, the Symmetry Theory of Valence, and Andrés’s CDNS model of experience.
These are risky predictions and we don’t yet know if they’re right, but we’re confident that if there is some elegant structure intrinsic to consciousness, as there is in many other parts of the natural world, these are the right kind of risks to take.
I mention all this because I think analytic functionalism- which is to say radical skepticism/eliminativism, the metaphysics of last resort- only looks as good as it does because nobody’s been building out any alternatives.
IV. Closing thoughts
FRI is pursuing a certain research agenda, and QRI is pursuing another, and there’s lots of value in independent explorations of the nature of suffering. I’m glad FRI exists, everybody I’ve interacted with at FRI has been great, I’m happy they’re focusing on s-risks, and I look forward to seeing what they produce in the future.
On the other hand, I worry that nobody’s pushing back on FRI’s metaphysics, which seem to unavoidably lead to the intractable problems I describe above. FRI seems to believe these problems are part of the territory, unavoidable messes that we just have to make philosophical peace with. But I think that functionalism is a bad map, that the metaphysical messes it leads to are much worse than most people realize (fatal to FRI’s mission), and there are other options that avoid these problems (which, to be fair, is not to say they have no problems).
Ultimately, FRI doesn’t owe me a defense of their position. But if they’re open to suggestions on what it would take to convince a skeptic like me that their brand of functionalism is viable, or at least rescuable, I’d offer the following:
Re: Objection 1 (motte-and-bailey), I suggest FRI should be as clear and complete as possible in their basic definition of suffering. In which particular ways is it ineffable/fuzzy, and in which particular ways is it precise? What can we definitely say about suffering, and what can we definitely never determine? Preregistering ontological commitments and methodological possibilities would help guard against FRI’s definition of suffering changing based on context.
Re: Objection 2 (intuition duels), FRI may want to internally “war game” various future scenarios involving AGI, WBE, etc, with one side arguing that a given synthetic (or even extraterrestrial) organism is suffering, and the other side arguing that it isn’t. I’d expect this would help diagnose what sorts of disagreements future theories of suffering will need to adjudicate, and perhaps illuminate implicit ethical intuitions. Sharing the results of these simulated disagreements would also be helpful in making FRI’s reasoning less opaque to outsiders, although making everything transparent could lead to certain strategic disadvantages.
Re: Objection 3 (convergence requires common truth), I’d like FRI to explore exactly might drive consilience/convergence in theories of suffering, and what precisely makes one theory of suffering better than another, and ideally to evaluate a range of example theories of suffering under these criteria.
Re: Objection 4 (assuming that consciousness is a reification produces more confusion, not less), I would love to see a historical treatment of reification: lists of reifications which were later dissolved (e.g., élan vital), vs scattered phenomena that were later unified (e.g., electromagnetism). What patterns do the former have, vs the latter, and why might consciousness fit one of these buckets better than the other?
Re: Objection 5 (the Hard Problem of Consciousness is a red herring), I’d like to see a more detailed treatment of what kinds of problem people have interpreted the Hard Problem as, and also more analysis on the prospects of Qualia Formalism (which I think is the maximally-empirical, maximally-charitable interpretation of the Hard Problem). It would be helpful for us, in particular, if FRI preregistered their expectations about QRI’s predictions, and their view of the relative evidence strength of each of our predictions.
Re: Objection 6 (mapping to reality), this is perhaps the heart of most of our disagreement. From Brian’s quotes, he seems split on this issue; I’d like clarification about whether he believes we can ever precisely/objectively map specific computations to specific physical systems, and vice-versa. And if so— how? If not, this seems to propagate through FRI’s ethical framework in a disastrous way, since anyone can argue that any physical system does, or does not, ‘code’ for massive suffering, and there’s no principled way derive any ‘ground truth’ or even pick between interpretations in a principled way (e.g. my popcorn example). If this isn’t the case— why not?
Brian has suggested that “certain high-level interpretations of physical systems are more ‘natural’ and useful than others” (personal communication); I agree, and would encourage FRI to explore systematizing this.
It would be non-trivial to port FRI’s theories and computational intuitions to the framework of “hypercomputation”-- i.e., the understanding that there’s a formal hierarchy of computational systems, and that Turing machines are only one level of many-- but it may have benefits too. Namely, it might be the only way they could avoid Objection 6 (which I think is a fatal objection) while still allowing them to speak about computation & consciousness in the same breath. I think FRI should look at this and see if it makes sense to them.
Re: Objection 7 (FRI doesn't fully bite the bullet on computationalism), I’d like to see responses to Aaronson’s aforementioned thought experiments.
Re: Objection 8 (dangerous combination), I’d like to see a clarification about why my interpretation is unreasonable (as it very well may be!).
---
In conclusion- I think FRI has a critically important goal- reduction of suffering & s-risk. However, I also think FRI has painted itself into a corner by explicitly disallowing a clear, disagreement-mediating definition for what these things are. I look forward to further work in this field.
---
Mike Johnson
Qualia Research Institute
Acknowledgements: thanks to Andrés Gomez Emilsson, Brian Tomasik, and Max Daniel for reviewing earlier drafts of this.
Sources:
My sources for FRI’s views on consciousness:
Flavors of Computation are Flavors of Consciousness:
https://foundational-research.org/flavors-of-computation-are-flavors-of-consciousness/
Is There a Hard Problem of Consciousness?
http://reducing-suffering.org/hard-problem-consciousness/
Consciousness Is a Process, Not a Moment
http://reducing-suffering.org/consciousness-is-a-process-not-a-moment/
How to Interpret a Physical System as a Mind
http://reducing-suffering.org/interpret-physical-system-mind/
Dissolving Confusion about Consciousness
http://reducing-suffering.org/dissolving-confusion-about-consciousness/
Debate between Brian & Mike on consciousness:
Max Daniel’s EA Global Boston 2017 talk on s-risks:
https://www.youtube.com/watch?v=jiZxEJcFExc
Multipolar debate between Eliezer Yudkowsky and various rationalists about animal suffering:
https://rationalconspiracy.com/2015/12/16/a-debate-on-animal-consciousness/
The Internet Encyclopedia of Philosophy on functionalism:
http://www.iep.utm.edu/functism/
Gordon McCabe on why computation doesn’t map to physics:
http://philsci-archive.pitt.edu/1891/1/UniverseCreationComputer.pdf
Toby Ord on hypercomputation, and how it differs from Turing’s work:
https://arxiv.org/abs/math/0209332
Luke Muehlhauser’s OpenPhil-funded report on consciousness and moral patienthood:
http://www.openphilanthropy.org/2017-report-consciousness-and-moral-patienthood
Scott Aaronson’s thought experiments on computationalism:
http://www.scottaaronson.com/blog/?p=1951
Selen Atasoy on Connectome Harmonics, a new way to understand brain activity:
https://www.nature.com/articles/ncomms10340
My work on formalizing phenomenology:
My meta-framework for consciousness, including the Symmetry Theory of Valence:
http://opentheory.net/PrincipiaQualia.pdf
My hypothesis of homeostatic regulation, which touches on why we seek out pleasure:
My exploration & parametrization of the ‘neuroacoustics’ metaphor suggested by Atasoy’s work:
http://opentheory.net/2017/06/taking-brain-waves-seriously-neuroacoustics/
My colleague Andrés’s work on formalizing phenomenology:
A model of DMT-trip-as-hyperbolic-experience:
https://qualiacomputing.com/2017/05/28/eli5-the-hyperbolic-geometry-of-dmt-experiences/
June 2017 talk at Consciousness Hacking, describing a theory and experiment to predict people’s valence from fMRI data:
https://qualiacomputing.com/2017/06/18/quantifying-bliss-talk-summary/
A parametrization of various psychedelic states as operators in qualia space:
https://qualiacomputing.com/2016/06/20/algorithmic-reduction-of-psychedelic-states/
A brief post on valence and the fundamental attribution error:
https://qualiacomputing.com/2016/11/19/the-tyranny-of-the-intentional-object/
A summary of some of Selen Atasoy’s current work on Connectome Harmonics:
https://qualiacomputing.com/2017/06/18/connectome-specific-harmonic-waves-on-lsd/
This was great and I really enjoyed reading it. It's a pleasure to see one EA disagreeing with another with such eloquence, kindness and depth.
What I would say is that, even as someone doing a PhD in Philosophy, I found a bunch of this hard to follow (I don't really do any work on consciousness), particularly objection 7 and when you introduced QRI's own approach. I'll entirely understand if you think making this more accessible is more trouble that it's worth, I just thought I'd let you know.
This looks sensible to me. I'd just quickly note that I'm not sure if it's quite accurate to describe this as "FRI's metaphysics", exactly - I work for FRI, but haven't been sold on the metaphysics that you're criticizing. In particular, I find myself skeptical of the premise "suffering is impossible to define objectively", which you largely focus on. (Though part of this may be simply because I haven't yet properly read/considered Brian's argument for it, so it's possible that I would change my mind about that.)
But in any case, I've currently got three papers in various stages of review, submission or preparation (that other FRI people have helped me with), and none of those papers presuppose this specific brand of metaphysics. There's a bunch of other work being done, too, which I know of and which I don't think presupposes it. So it doesn't feel quite accurate to me to suggest that the metaphysics would be holding back our progress, though of course there can be some research being carried out that's explicitly committed to this particular metaphysics.
(opinions in this comment purely mine, not an official FRI statement etc.)
This sounds right. Before 2016, I would have said that rough value alignment (normatively "suffering-focused") is very-close-to necessary, but we updated away from this condition and for quite some time now hold the view that it is not essential if people are otherwise a good fit. We still have an expectation that researchers think about research-relevant background assumptions in ways that are not completely different from ours on every issue, but single disagreements are practically never a dealbreaker. We've had qualia realists both on the team (part-time) and as interns, and some team members now don't hold strong views on the issue one way or the other. Brian especially is a really strong advocate of epistemic diversity and goes much further with it than I feel most people would go.
Hm, this does not fit my observations. We had and still ... (read more)
Rather than put words in the mouths of other people at FRI, I'd rather let them personally answer which philosophical premises they accept and what motivates them, if they wish.
For me personally, I've just had, for a long time, the intuition that preventing extreme suffering is the most important priority. To the best that I can tell, much of this intuition can be traced to having suffered from depression and general feelings of crushing hopelessness for large parts of my life, and wanting to save anyone else from experiencing a similar (or worse!) magnitude of suffering. I seem to recall that I was less suffering-focused before I started getting depressed for the first time.
Since then, that intuition has been reinforced by reading up on other suffering-focused works; something like tranquilism feels like a sensible theory to me, especially given some of my own experiences with meditation which are generally compatible with the kind of theory of mind implied by tranquilism. That's something that has come later, though.
To clarify, none of this means that I would only value suffering prevention: I'd much rather see a universe-wide flourishing civilization full of minds in various sta... (read more)
What's the problem if a group of people explores the implications of a well-respected position in philosophy and are (I think) fully aware of the implications? Exploring a different position should be a task for people who actually place more than a tiny bit of credence in it, it seems to me - especially when it comes to a new and speculative hypothesis like principle qualia.
This post mostly reads like a contribution to a long-standing philosophical debate to me and would be more appropriately presented as arguing against a philosophical assumption rather than against a research group working under that assumption.
In the cog-sci / neuroscience institute where I currently work, productive work is being done under similar, though less explicit, assumptions as Brian's / FRI's. Including relevant work on modelling valence in animals in the reinforcement learning framework.
I know you disagree with these assumptions but a post like this can make it seem to outsiders as if you're criticizing a somewhat crazy position and by extension cast a bad light on FRI.
Brian's view is maybe best described as eliminativism about consciousness (which may already seem counterintuitive to many) plus a counterintuitive way to draw boundaries in concept space. Luke Muehlhauser said about Brian's way of assigning non-zero moral relevance to any process that remotely resembles aspects of our concept of consciousness:
"Mr. Tomasik’s view [...] amounts to pansychism about consciousness as an uninformative special case of “pan-everythingism about everything."
See this conversation.
So the disagreement there does not appear to be about questions such as "What produces people's impression of there being a hard problem of consciousness?," but rather whether anything that is "non-infinitely separated in multi-dimensional concept space" still deserves some (tiny) recognition as fitting into the definition. As Luke says here, the concept "consciousness" works more like "life" (= fuzzy) and less like "water" (= H2O), and so if one shares this view, it becomes non-trivial to come up with an all-encompassing definition.
While most (? my impression anyway as someone who works there) researchers at FRI place... (read more)
Speaking of the metaphysical correctness of claims about qualia sounds confused, and I think precise definitions of qualia-related terms should be judged by how useful they are for generalizing our preferences about central cases. I expect that any precise definition for qualia-related terms that anyone puts forward before making quite a lot of philosophical progress is going to be very wrong when judged by usefulness for describing preferences, and that the vagueness of the analytic functionalism used by FRI is necessary to avoid going far astray.
Regardin... (read more)
Interesting that you mention the "waterfall"/"bag of popcorn" argument against computationalism in the same article as citing Scott Aaronson, since he actually gives some arguments against it (see section 6 of https://arxiv.org/abs/1108.1791). In particular, he suggests that we can argue that a process P isn't contributing any computation when having a P-oracle doesn't let you solve the problem faster.
I don't think this fully lays to rest the question of what things are performing computations, but I think we can distinguish them in som... (read more)
I'm a bit surprised to find that Brian Tomasik attributes his current views on consciousness to his conversations with Carl Shulman, since in my experience Carl is a very careful thinker and the case for accepting anti-realism as the answer to the problem of consciousness seems pretty weak, at least as explained by Brian. I'm very curious to read Carl's own explanation of his views, if he has written one down. I scanned Carl Shulman's list of writings but was unable to find anything that addressed this.
Aside:
I don't see how this can work given (I think) isomorphism is transitive and there are lots of isomorphisms between sets of mathematical objects which will not preserve symmetry.
Toy example. Say we can map the set of all phenomen... (read more)
Curious for your take on the premise that ontologies always have tacit telos.
Also, we desire to expand the domains of our perception with scientific instrumentation and abstractions. This expansion always generates some mapping (ontology) from the new data to our existing sensory modalities.
I think this is relevant for the dissonance model of suffering, though I can't fully articulate how yet.
I'm a little confused here. Where does MIRI or FHI say anything about consciousness, much less assume any particular view?
Re: 2, I don't see how we should expect functionalism to resolve disputes over which agents are conscious. Panpsychism does not such thing, nor does physicalism or dualism or any other theory of mind. Any of these theories can inform inquiry about which agents are conscious, in tandem with empirical work, but the connection is tenuous and it seems to me that at least 70% of the work is empirical. Theory of mind mostly gives a theoretical basis for empirical work.
The problem lies more with the specific anti-realist account of sentience that some people at F... (read more)
This is a super interesting article, but...
To me, it reads like it was written by someone who has never really encountered suffering.
http://www.mattball.org/2014/11/excerpts-from-letter-to-young-matt.html