I recently gave a talk at Google on the problem of aligning smarter-than-human AI with operators' goals. Below is a modified transcript, in case people here are interested. I think it provides a decent introduction to "AI risk" as a cause-area worthy of attention from effective altruists. I post it here in case anyone wants to link it to curious EAs. Note that this is a cross-post from the MIRI blog, and that you can also watch the talk on YouTube. The talk was inspired by “AI Alignment: Why It's Hard, and Where to Start.” The slides of the talk are available here.
Outline:
1. Overview
2. Simple Bright Ideas Going Wrong
2.2. Subproblem: Suspend Buttons
3.1. Alignment Priorities
Overview
I'm the executive director of the Machine Intelligence Research Institute. Very roughly speaking, we're a group that's thinking in the long term about artificial intelligence and working to make sure that by the time we have advanced AI systems, we also know how to point them in useful directions.
Across history, science and technology have been the largest drivers of change in human and animal welfare, for better and for worse. If we can automate scientific and technological innovation, that has the potential to change the world on a scale not seen since the Industrial Revolution. When I talk about “advanced AI,” it's this potential for automating innovation that I have in mind.
AI systems that exceed humans in this capacity aren't coming next year, but many smart people are working on it, and I'm not one to bet against human ingenuity. I think it's likely that we'll be able to build something like an automated scientist in our lifetimes, which suggests that this is something we need to take seriously.
When people talk about the social implications of general AI, they often fall prey to anthropomorphism. They conflate artificial intelligence with artificial consciousness, or assume that if AI systems are “intelligent,” they must be intelligent in the same way a human is intelligent. A lot of journalists express a concern that when AI systems pass a certain capability level, they'll spontaneously develop “natural” desires like a human hunger for power; or they'll reflect on their programmed goals, find them foolish, and “rebel,” refusing to obey their programmed instructions.
These are misplaced concerns. The human brain is a complicated product of natural selection. We shouldn't expect machines that exceed human performance in scientific innovation to closely resemble humans, any more than early rockets, airplanes, or hot air balloons closely resembled birds. 1
The notion of AI systems “breaking free” of the shackles of their source code or spontaneously developing human-like desires is just confused. The AI system is its source code, and its actions will only ever follow from the execution of the instructions that we initiate. The CPU just keeps on executing the next instruction in the program register. We could write a program that manipulates its own code, including coded objectives. Even then, though, the manipulations that it makes are made as a result of executing the original code that we wrote; they do not stem from some kind of ghost in the machine.
The serious question with smarter-than-human AI is how we can ensure that the objectives we've specified are correct, and how we can minimize costly accidents and unintended consequences in cases of misspecification. As Stuart Russell (co-author of Artificial Intelligence: A Modern Approach) puts it:
“The primary concern is not spooky emergent consciousness but simply the ability to make high-quality decisions.”
Here, quality refers to the expected outcome utility of actions taken, where the utility function is, presumably, specified by the human designer. Now we have a problem:
- The utility function may not be perfectly aligned with the values of the human race, which are (at best) very difficult to pin down.
- Any sufficiently capable intelligent system will prefer to ensure its own continued existence and to acquire physical and computational resources – not for their own sake, but to succeed in its assigned task.
A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable.
These kinds of concerns deserve a lot more attention than the more anthropomorphic risks that are generally depicted in Hollywood blockbusters.
Simple Bright Ideas Going Wrong
Task: Fill a Cauldron
Many people, when they start talking about concerns with smarter-than-human AI, will throw up a picture of the Terminator. I was once quoted in a news article making fun of people who put up Terminator pictures in all their articles about AI, next to a Terminator picture. I learned something about the media that day.
I think this is a much better picture:

This is Mickey Mouse in the movie Fantasia, who has very cleverly enchanted a broom to fill a cauldron on his behalf.
How might Mickey do this? We can imagine that Mickey writes a computer program and has the broom execute the program. Mickey starts by writing down a scoring function or objective function:
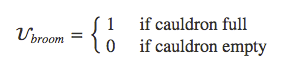
Given some set 𝐴 of available actions, Mickey then writes a program that can take one of these actions 𝑎 as input and calculate how high the score is expected to be if the broom takes that action. Then Mickey can write a function that spends some time looking through actions and predicting which ones lead to high scores, and outputs an action that leads to a relatively high score:
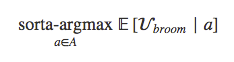
The reason this is “sorta-argmax” is that there may not be time to evaluate every action in 𝐴. For realistic action sets, agents should only need to find actions that make the scoring function as large as they can given resource constraints, even if this isn't the maximal action.
This program may look simple, but of course, the devil's in the details: writing an algorithm that does accurate prediction and smart search through action space is basically the whole problem of AI. Conceptually, however, it's pretty simple: We can describe in broad strokes the kinds of operations the broom must carry out, and their plausible consequences at different performance levels. When Mickey runs this program, everything goes smoothly at first. Then:

I claim that as fictional depictions of AI go, this is pretty realistic.
Why would we expect a generally intelligent system executing the above program to start overflowing the cauldron, or otherwise to go to extreme lengths to ensure the cauldron is full?
The first difficulty is that the objective function that Mickey gave his broom left out a bunch of other terms Mickey cares about:

The second difficulty is that Mickey programmed the broom to make the expectation of its score as large as it could. “Just fill one cauldron with water” looks like a modest, limited-scope goal, but when we translate this goal into a probabilistic context, we find that optimizing it means driving up the probability of success to absurd heights. If the broom assigns a 99.9% probability to “the cauldron is full,” and it has extra resources lying around, then it will always try to find ways to use those resources to drive the probability even a little bit higher.
Contrast this with the limited “task-like” goal we presumably had in mind. We wanted the cauldron full, but in some intuitive sense we wanted the system to “not try too hard” even if it has lots of available cognitive and physical resources to devote to the problem. We wanted it to exercise creativity and resourcefulness within some intuitive limits, but we didn't want it to pursue “absurd” strategies, especially ones with large unanticipated consequences. 2
In this example, the original objective function looked pretty task-like. It was bounded and quite simple. There was no way to get ever-larger amounts of utility. It's not like the system got one point for every bucket of water it poured in — then there would clearly be an incentive to overfill the cauldron. The problem was hidden in the fact that we're maximizing expected utility. This makes the goal open-ended, meaning that even small errors in the system's objective function will blow up.
There are a number of different ways that a goal that looks task-like can turn out to be open-ended. Another example: a larger system that has an overarching task-like goal may have subprocesses that are themselves trying to maximize a variety of different objective functions, such as optimizing the system's memory usage. If you don't understand your system well enough to track whether any of its subprocesses are themselves acting like resourceful open-ended optimizers, then it may not matter how safe the top-level objective is.
So the broom keeps grabbing more pails of water — say, on the off chance that the cauldron has a leak in it, or that “fullness” requires the water to be slightly above the level of the brim. And, of course, at no point does the broom “rebel against” Mickey's code. If anything, the broom pursued the objectives it was programmed with too effectively.
Subproblem: Suspend Buttons
A common response to this problem is: “OK, there may be some unintended consequences of the objective function, but we can always pull the plug, right?”
Mickey tries this, and it doesn't work:



And I claim that this is realistic too, for systems that are sufficiently good at modeling their environment. If the system is trying to drive up the expectation of its scoring function and is smart enough to recognize that its being shut down will result in lower-scoring outcomes, then the system's incentive is to subvert shutdown attempts. The more capable the system is, the likelier it is to find creative ways to achieve that subgoal — e.g., by copying itself to the Internet, or by tricking the programmers into thinking it's safer.
This isn't to say that it's impossible to shut down sufficiently capable AI systems; it's just that we need to put in the extra work of deliberately designing systems to avoid searching for ways to avoid being shut down. If you've written code that would try to resist attempts to shut it down, then you shouldn't run the code even if you're convinced it would fail — there are better ways to spend those compute cycles than on adversarial policy searches.
Relevant safety measures that don't assume we can always outthink and outmaneuver the system will need to modify the system's objective function in some relevant way. We need to figure out how to formally specify objective functions that don't automatically place the AI system into an adversarial context with the operators; or we need to figure out some way to have the system achieve goals without optimizing some objective function in the traditional sense. E.g., we can look for ways to limit the system's capabilities to a small set of “whitelisted” domains that don't include thinking about whether the system will be shut down.
One obvious solution is to try changing the score function to make reference to a suspend button 𝐁:

This says that when the button is on, the system's goal changes from “fill the cauldron” to “be suspended.”
It's not clear how we could actually specify this goal — if there are any loopholes in the way we've specified “suspension,” then the system might try to exploit them to hedge its bets. E.g., it could fulfill the technical definition of “suspend operations” while tasking a child agent it built or subprocess it started with filling the cauldron. This would allow is to achieve both “cauldron full” and “robot suspended” at once, just in case it's wrong about whether the button has been pushed.
Let's assume, however, that we've found an airtight way to technically specify suspension. The problem we run into now is that we've given the system an incentive to care a lot about whether the button is pushed. If it has any way to influence its operators' decision to push the button, or any other way to exercise more control, then it will jump on the opportunity and try to ensure the button is pushed, or ensure that it's not pushed — depending on whether it looks easier to suspend or to fill the cauldron.
And, surprisingly, the state of the art on this problem isn't much more advanced than that. There's a paper co-authored by me, Fallenstein, Yudkowsky, and Armstrong (“Corrigibility“), and a related result by Orseau and Armstrong (“Safely Interruptible Agents“), but not a lot more.
What we want is a way to combine two objective functions — a default function for normal operation, and a suspend function for when we want to suspend the system to disk.
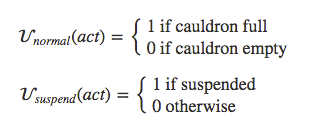
We want our method for combining the functions to satisfy three conditions: an operator should be able to switch between the functions (say, by pushing a button); the system shouldn't have any incentives to control which function is active; and if it's plausible that the system's normal operations could inadvertently compromise our ability to switch between the functions, then the system should be incentivized to keep that from happening.
So far, we haven't found any way to achieve all three goals at once. As an example, we can try to remove any incentive on the system's part to control whether its suspend button is pushed by giving the system a switching objective function that always assigns the same expected utility to the button being on or off:
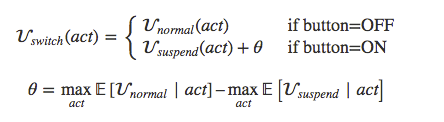
Unfortunately, this approach makes it impossible to satisfy the third condition. It turns out that the above objective function is equivalent to setting the probability of the button being pressed to 0. The system won't deliberately tamper with the button, but it will happily approve updates that delete any reference to the button as dead code, or build subagents that ignore the button.
Meeting these intuitively simple constraints turns out to be a nontrivial problem. This is a pattern that runs through a lot of questions in this space: traditional tools and concepts run into immediate safety problems that don't turn up in conventional capabilities research.
The Big Picture
Alignment Priorities
Let's take a step back and talk about what's needed overall in order to align highly capable AI systems with our interests.
Here's a dramatically simplified pipeline: You have some humans who come up with some task or goal or preference set that serves as their intended value function 𝘝. Since our values are complicated and context-sensitive, in practice we'll need to build systems to learn our values over time, rather than coding them by hand. 3 We'll call the goal the AI system ends up with (which may or may not be identical to 𝘝) 𝗨.

When the press covers this topic, they often focus on one of two problems: “What if the wrong group of humans develops smarter-than-human AI first?”, and “What if AI's natural desires cause 𝗨 to diverge from 𝘝?”
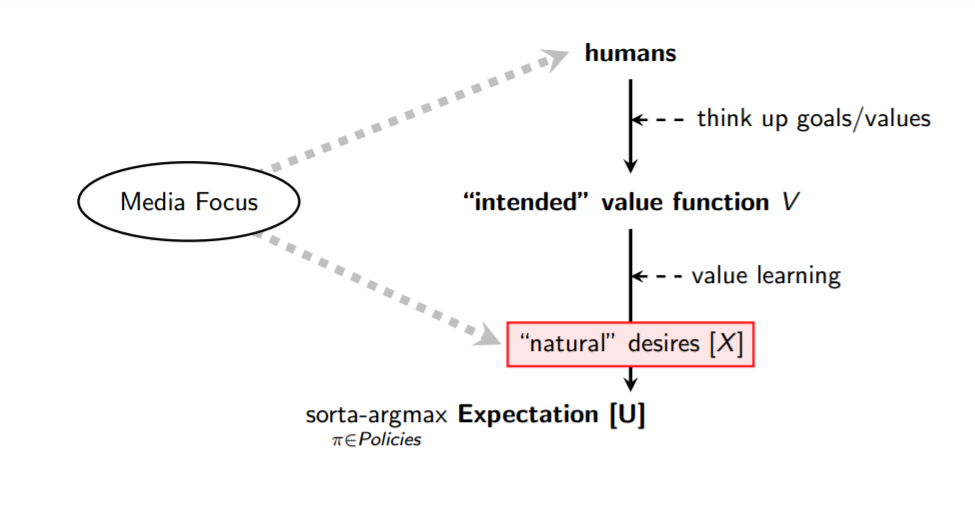
In my view, the “wrong humans” issue shouldn't be the thing we focus on until we have reason to think we could get good outcomes with the right group of humans. We're very much in a situation where well-intentioned people couldn't leverage a general AI system to do good things even if they tried. As a simple example, if you handed me a box that was an extraordinarily powerful function optimizer — I could put in a description of any mathematical function, and it would give me an input that makes the output extremely large — then I do know how to use the box to produce a random catastrophe, but I don't actually know how I could use that box in the real world to have a good impact. 4
There's a lot we don't understand about AI capabilities, but we're in a position where we at least have a general sense of what progress looks like. We have a number of good frameworks, techniques, and metrics, and we've put a great deal of thought and effort into successfully chipping away at the problem from various angles. At the same time, we have a very weak grasp on the problem of how to align highly capable systems with any particular goal. We can list out some intuitive desiderata, but the field hasn't really developed its first formal frameworks, techniques, or metrics.
I believe that there's a lot of low-hanging fruit in this area, and also that a fair amount of the work does need to be done early (e.g., to help inform capabilities research directions — some directions may produce systems that are much easier to align than others). If we don't solve these problems, developers with arbitrarily good or bad intentions will end up producing equally bad outcomes. From an academic or scientific standpoint, our first objective in that kind of situation should be to remedy this state of affairs and at least make good outcomes technologically possible.
Many people quickly recognize that “natural desires” are a fiction, but infer from this that we instead need to focus on the other issues the media tends to emphasize — “What if bad actors get their hands on smarter-than-human AI?”, “How will this kind of AI impact employment and the distribution of wealth?”, etc. These are important questions, but they'll only end up actually being relevant if we figure out how to bring general AI systems up to a minimum level of reliability and safety.
Another common thread is “Why not just tell the AI system to (insert intuitive moral precept here)?” On this way of thinking about the problem, often (perhaps unfairly) associated with Isaac Asimov's writing, ensuring a positive impact from AI systems is largely about coming up with natural-language instructions that are vague enough to subsume a lot of human ethical reasoning:

In contrast, precision is a virtue in real-world safety-critical software systems. Driving down accident risk requires that we begin with limited-scope goals rather than trying to “solve” all of morality at the outset. 5
My view is that the critical work is mostly in designing an effective value learning process, and in ensuring that the sorta-argmax process is correctly hooked up to the resultant objective function 𝗨:
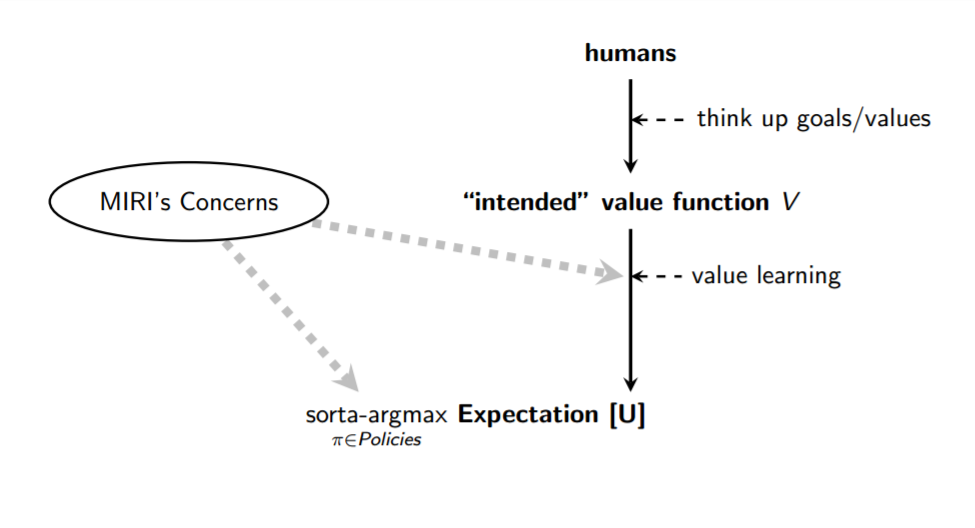
The better your value learning framework is, the less explicit and precise you need to be in pinpointing your value function 𝘝, and the more you can offload the problem of figuring out what you want to the AI system itself. Value learning, however, raises a number of basic difficulties that don't crop up in ordinary machine learning tasks.
Classic capabilities research is concentrated in the sorta-argmax and Expectation parts of the diagram, but sorta-argmax also contains what I currently view as the most neglected, tractable, and important safety problems. The easiest way to see why “hooking up the value learning process correctly to the system's capabilities” is likely to be an important and difficult challenge in its own right is to consider the case of our own biological history.
Natural selection is the only “engineering” process we know of that has ever led to a generally intelligent artifact: the human brain. Since natural selection relies on a fairly unintelligent hill-climbing approach, one lesson we can take away from this is that it's possible to reach general intelligence with a hill-climbing approach and enough brute force — though we can presumably do better with our human creativity and foresight.
Another key take-away is that natural selection was maximally strict about only optimizing brains for a single very simple goal: genetic fitness. In spite of this, the internal objectives that humans represent as their goals are not genetic fitness. We have innumerable goals — love, justice, beauty, mercy, fun, esteem, good food, good health, … — that correlated with good survival and reproduction strategies in the ancestral savanna. However, we ended up valuing these correlates directly, rather than valuing propagation of our genes as an end in itself — as demonstrated every time we employ birth control.
This is a case where the external optimization pressure on an artifact resulted in a general intelligence with internal objectives that didn't match the external selection pressure. And just as this caused humans' actions to diverge from natural selection's pseudo-goal once we gained new capabilities, we can expect AI systems' actions to diverge from humans' if we treat their inner workings as black boxes.
If we apply gradient descent to a black box, trying to get it to be very good at maximizing some objective, then with enough ingenuity and patience, we may be able to produce a powerful optimization process of some kind. 6 By default, we should expect an artifact like that to have a goal 𝗨 that strongly correlates with our objective 𝘝 in the training environment, but sharply diverges from 𝘝 in some new environments or when a much wider option set becomes available.
On my view, the most important part of the alignment problem is ensuring that the value learning framework and overall system design we implement allow us to crack open the hood and confirm when the internal targets the system is optimizing for match (or don't match) the targets we're externally selecting through the learning process. 7
We expect this to be technically difficult, and if we can't get it right, then it doesn't matter who's standing closest to the AI system when it's developed. Good intentions aren't sneezed into computer programs by kind-hearted programmers, and coming up with plausible goals for advanced AI systems doesn't help if we can't align the system's cognitive labor with a given goal.
Four Key Propositions
Taking another step back: I've given some examples of open problems in this area (suspend buttons, value learning, limited task-based AI, etc.), and I've outlined what I consider to be the major problem categories. But my initial characterization of why I consider this an important area — “AI could automate general-purpose scientific reasoning, and general-purpose scientific reasoning is a big deal” — was fairly vague. What are the core reasons to prioritize this work?
First, goals and capabilities are orthogonal. That is, knowing an AI system's objective function doesn't tell you how good it is at optimizing that function, and knowing that something is a powerful optimizer doesn't tell you what it's optimizing.
I think most programmers intuitively understand this. Some people will insist that when a machine tasked with filling a cauldron gets smart enough, it will abandon cauldron-filling as a goal unworthy of its intelligence. From a computer science perspective, the obvious response is that you could go out of your way to build a system that exhibits that conditional behavior, but you could also build a system that doesn't exhibit that conditional behavior. It can just keeps searching for actions that have a higher score on the “fill a cauldron” metric. You and I might get bored if someone told us to just keep searching for better actions, but it's entirely possible to write a program that executes a search and never gets bored. 8
Second, sufficiently optimized objectives tend to converge on adversarial instrumental strategies. Most objectives a smarter-than-human AI system could possess would be furthered by subgoals like “acquire resources” and “remain operational” (along with “learn more about the environment,” etc.).
This was the problem suspend buttons ran into: even if you don't explicitly include “remain operational” in your goal specification, whatever goal you did load into the system is likely to be better achieved if the system remains online. Software systems' capabilities and (terminal) goals are orthogonal, but they'll often exhibit similar behaviors if a certain class of actions is useful for a wide variety of possible goals.
To use an example due to Stuart Russell: If you build a robot and program it to go to the supermarket to fetch some milk, and the robot's model says that one of the paths is much safer than the other, then the robot, in optimizing for the probability that it returns with milk, will automatically take the safer path. It's not that the system fears death, but that it can't fetch the milk if it's dead.
Third, general-purpose AI systems are likely to show large and rapid capability gains. The human brain isn't anywhere near the upper limits for hardware performance (or, one assumes, software performance), and there are a number of other reasons to expect large capability advantages and rapid capability gain from advanced AI systems.
As a simple example, Google can buy a promising AI startup and throw huge numbers of GPUs at them, resulting in a quick jump from “these problems look maybe relevant a decade from now” to “we need to solve all of these problems in the next year.” 9
Fourth, aligning advanced AI systems with our interests looks difficult. I'll say more about why I think this presently.
Roughly speaking, the first proposition says that AI systems won't naturally end up sharing our objectives. The second says that by default, systems with substantially different objectives are likely to end up adversarially competing for control of limited resources. The third suggests that adversarial general-purpose AI systems are likely to have a strong advantage over humans. And the fourth says that this problem is hard to solve — for example, that it's hard to transmit our values to AI systems (addressing orthogonality) or avert adversarial incentives (addressing convergent instrumental strategies).
These four propositions don't mean that we're screwed, but they mean that this problem is critically important. General-purpose AI has the potential to bring enormous benefits if we solve this problem, but we do need to make finding solutions a priority for the field.
Fundamental Difficulties
Why do I think that AI alignment looks fairly difficult? The main reason is just that this has been my experience from actually working on these problems. I encourage you to look at some of the problems yourself and try to solve them in toy settings; we could use more eyes here. I'll also make note of a few structural reasons to expect these problems to be hard:
First, aligning advanced AI systems with our interests looks difficult for the same reason rocket engineering is more difficult than airplane engineering.
Before looking at the details, it's natural to think “it's all just AI” and assume that the kinds of safety work relevant to current systems are the same as the kinds you need when systems surpass human performance. On that view, it's not obvious that we should work on these issues now, given that they might all be worked out in the course of narrow AI research (e.g., making sure that self-driving cars don't crash).
Similarly, at a glance someone might say, “Why would rocket engineering be fundamentally harder than airplane engineering? It's all just material science and aerodynamics in the end, isn't it?” In spite of this, empirically, the proportion of rockets that explode is far higher than the proportion of airplanes that crash. The reason for this is that a rocket is put under much greater stress and pressure than an airplane, and small failures are much more likely to be highly destructive. 10
Analogously, even though general AI and narrow AI are “just AI” in some sense, we can expect that the more general AI systems are likely to experience a wider range of stressors, and possess more dangerous failure modes.
For example, once an AI system begins modeling the fact that (i) your actions affect its ability to achieve its objectives, (ii) your actions depend on your model of the world, and (iii) your model of the world is affected by its actions, the degree to which minor inaccuracies can lead to harmful behavior increases, and the potential harmfulness of its behavior (which can now include, e.g., deception) also increases. In the case of AI, as with rockets, greater capability makes it easier for small defects to cause big problems.
Second, alignment looks difficult for the same reason it's harder to build a good space probe than to write a good app.
You can find a number of interesting engineering practices at NASA. They do things like take three independent teams, give each of them the same engineering spec, and tell them to design the same software system; and then they choose between implementations by majority vote. The system that they actually deploy consults all three systems when making a choice, and if the three systems disagree, the choice is made by majority vote. The idea is that any one implementation will have bugs, but it's unlikely all three implementations will have a bug in the same place.
This is significantly more caution than goes into the deployment of, say, the new WhatsApp. One big reason for the difference is that it's hard to roll back a space probe. You can send version updates to a space probe and correct software bugs, but only if the probe's antenna and receiver work, and if all the code required to apply the patch is working. If your system for applying patches is itself failing, then there's nothing to be done.
In that respect, smarter-than-human AI is more like a space probe than like an ordinary software project. If you're trying to build something smarter than yourself, there are parts of the system that have to work perfectly on the first real deployment. We can do all the test runs we want, but once the system is out there, we can only make online improvements if the code that makes the system allow those improvements is working correctly.
If nothing yet has struck fear into your heart, I suggest meditating on the fact that the future of our civilization may well depend on our ability to write code that works correctly on the first deploy.
Lastly, alignment looks difficult for the same reason computer security is difficult: systems need to be robust to intelligent searches for loopholes.
Suppose you have a dozen different vulnerabilities in your code, none of which is itself fatal or even really problematic in ordinary settings. Security is difficult because you need to account for intelligent attackers who might find all twelve vulnerabilities and chain them together in a novel way to break into (or just break) your system. Failure modes that would never arise by accident can be sought out and exploited; weird and extreme contexts can be instantiated by an attacker to cause your code to follow some crazy code path that you never considered.
A similar sort of problem arises with AI. The problem I'm highlighting here is not that AI systems might act adversarially: AI alignment as a research program is all about finding ways to prevent adversarial behavior before it can crop up. We don't want to be in the business of trying to outsmart arbitrarily intelligent adversaries. That's a losing game.
The parallel to cryptography is that in AI alignment we deal with systems that perform intelligent searches through a very large search space, and which can produce weird contexts that force the code down unexpected paths. This is because the weird edge cases are places of extremes, and places of extremes are often the place where a given objective function is optimized. 11 Like computer security professionals, AI alignment researchers need to be very good at thinking about edge cases.
It's much easier to make code that works well on the path that you were visualizing than to make code that works on all the paths that you weren't visualizing. AI alignment needs to work on all the paths you weren't visualizing.
Summing up, we should approach a problem like this with the same level of rigor and caution we'd use for a security-critical rocket-launched space probe, and do the legwork as early as possible. At this early stage, a key part of the work is just to formalize basic concepts and ideas so that others can critique them and build on them. It's one thing to have a philosophical debate about what kinds of suspend buttons people intuit ought to work, and another thing to translate your intuition into an equation so that others can fully evaluate your reasoning.
This is a crucial project, and I encourage all of you who are interested in these problems to get involved and try your hand at them. There are ample resources online for learning more about the open technical problems. Some good places to start include MIRI's research agendas and a great paper from researchers at Google Brain, OpenAI, and Stanford called “Concrete Problems in AI Safety.”
Footnotes
1 An airplane can't heal its injuries or reproduce, though it can carry heavy cargo quite a bit further and faster than a bird. Airplanes are simpler than birds in many respects, while also being significantly more capable in terms of carrying capacity and speed (for which they were designed). It's plausible that early automated scientists will likewise be simpler than the human mind in many respects, while being significantly more capable in certain key dimensions. And just as the construction and design principles of aircraft look alien relative to the architecture of biological creatures, we should expect the design of highly capable AI systems to be quite alien when compared to the architecture of the human mind. ↩
2 Trying to give some formal content to these attempts to differentiate task-like goals from open-ended goals is one way of generating open research problems. In the “Alignment for Advanced Machine Learning Systems” research proposal, the problem of formalizing “don't try too hard” is mild optimization, “steer clear of absurd strategies” is conservatism, and “don't have large unanticipated consequences” is impact measures. See also “avoiding negative side effects” in Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané's “Concrete Problems in AI Safety.” ↩
3 One thing we've learned in the field of machine vision over the last few decades is that it's hopeless to specify by hand what a cat looks like, but that it's not too hard to specify a learning system that can learn to recognize cats. It's even more hopeless to specify everything we value by hand, but it's plausible that we could specify a learning system that can learn the relevant concept of “value.” ↩
4 Roughly speaking, MIRI's focus is on research directions that seem likely to help us conceptually understand how to do AI alignment in principle, so we're fundamentally less confused about the kind of work that's likely to be needed.
What do I mean by this? Let's say that we're trying to develop a new chess-playing programs. Do we understand the problem well enough that we could solve it if someone handed us an arbitrarily large computer? Yes: We make the whole search tree, backtrack, see whether white has a winning move.
If we didn't know how to answer the question even with an arbitrarily large computer, then this would suggest that we were fundamentally confused about chess in some way. We'd either be missing the search-tree data structure or the backtracking algorithm, or we'd be missing some understanding of how chess works.
This was the position we were in regarding chess prior to Claude Shannon's seminal paper, and it's the position we're currently in regarding many problems in AI alignment. No matter how large a computer you hand me, I could not make a smarter-than-human AI system that performs even a very simple limited-scope task (e.g., “put a strawberry on a plate without producing any catastrophic side-effects”) or achieves even a very simple open-ended goal (e.g., “maximize the amount of diamond in the universe”).
If I didn't have any particular goal in mind for the system, I could write a program (assuming an arbitrarily large computer) that strongly optimized the future in an undirected way, using a formalism like AIXI. In that sense we're less obviously confused about capabilities than about alignment, even though we're still missing a lot of pieces of the puzzle on the practical capabilities front.
Our goal is to develop and formalize basic approaches and ways of thinking about the alignment problem, so that our engineering decisions don't end up depending on sophisticated and clever-sounding verbal arguments that turn out to be subtly mistaken. Simplifications like “what if we weren't worried about resource constraints?” and “what if we were trying to achieve a much simpler goal?” are a good place to start breaking down the problem into manageable pieces. For more on this methodology, see “MIRI's Approach.” ↩
5 “Fill this cauldron without being too clever about it or working too hard or having any negative consequences I'm not anticipating” is a rough example of a goal that's intuitively limited in scope. The things we actually want to use smarter-than-human AI for are obviously more ambitious than that, but we'd still want to begin with various limited-scope tasks rather than open-ended goals.
Asimov's Three Laws of Robotics make for good stories partly for the same reasons they're unhelpful from a research perspective. The hard task of turning a moral precept into lines of code is hidden behind phrasings like “[don't,] through inaction, allow a human being to come to harm.” If one followed a rule like that strictly, the result would be massively disruptive, as AI systems would need to systematically intervene to prevent even the smallest risks of even the slightest harms; and if the intent is that one follow the rule loosely, then all the work is being done by the human sensibilities and intuitions that tell us when and how to apply the rule.
A common response here is that vague natural-language instruction is sufficient, because smarter-than-human AI systems are likely to be capable of natural language comprehension. However, this is eliding the distinction between the system's objective function and its model of the world. A system acting in an environment containing humans may learn a world-model that has lots of information about human language and concepts, which the system can then use to achieve its objective function; but this fact doesn't imply that any of the information about human language and concepts will “leak out” and alter the system's objective function directly.
Some kind of value learning process needs to be defined where the objective function itself improves with new information. This is a tricky task because there aren't known (scalable) metrics or criteria for value learning in the way that there are for conventional learning.
If a system's world-model is accurate in training environments but fails in the real world, then this is likely to result in lower scores on its objective function — the system itself has an incentive to improve. The severity of accidents is also likelier to be self-limiting in this case, since false beliefs limit a system's ability to effectively pursue strategies.
In contrast, if a system's value learning process results in a 𝗨 that matches our 𝘝 in training but diverges from 𝘝 in the real world, then the system's 𝗨 will obviously not penalize it for optimizing 𝗨. The system has no incentive relative to 𝗨 to “correct” divergences between 𝗨 and 𝘝, if the value learning process is initially flawed. And accident risk is larger in this case, since a mismatch between 𝗨 and 𝘝 doesn't necessarily place any limits on the system's instrumental effectiveness at coming up with effective and creative strategies for achieving 𝗨.
The problem is threefold:
- “Do What I Mean” is an informal idea, and even if we knew how to build a smarter-than-human AI system, we wouldn't know how to precisely specify this idea in lines of code.
- If doing what we actually mean is instrumentally useful for achieving a particular objective, then a sufficiently capable system may learn how to do this, and may act accordingly so long as doing so is useful for its objective. But as systems become more capable, they are likely to find creative new ways to achieve the same objectives, and there is no obvious way to get an assurance that “doing what I mean” will continue to be instrumentally useful indefinitely.
- If we use value learning to refine a system's goals over time based on training data that appears to be guiding the system toward a 𝗨 that inherently values doing what we mean, it is likely that the system will actually end up zeroing in on a 𝗨 that approximately does what we mean during training but catastrophically diverges in some difficult-to-anticipate contexts. See “Goodhart's Curse” for more on this.
For examples of problems faced by existing techniques for learning goals and facts, such as reinforcement learning, see “Using Machine Learning to Address AI Risk.” ↩
6 The result will probably not be a particularly human-like design, since so many complex historical contingencies were involved in our evolution. The result will also be able to benefit from a number of large software and hardware advantages. ↩
7 This concept is sometimes lumped into the “transparency” category, but standard algorithmic transparency research isn't really addressing this particular problem. A better term for what I have in mind here is “understanding.” What we want is to gain deeper and broader insights into the kind of cognitive work the system is doing and how this work relates to the system's objectives or optimization targets, to provide a conceptual lens with which to make sense of the hands-on engineering work. ↩
8 We could choose to program the system to tire, but we don't have to. In principle, one could program a broom that only ever finds and executes actions that optimize the fullness of the cauldron. Improving the system's ability to efficiently find high-scoring actions (in general, or relative to a particular scoring rule) doesn't in itself change the scoring rule it's using to evaluate actions. ↩
9 Some other examples: a system's performance may suddenly improve when it's first given large-scale Internet access, when there's a conceptual breakthrough in algorithm design, or when the system itself is able to propose improvements to its hardware and software. We can imagine the latter case in particular resulting in a feedback loop as the system's design improvements allow it to come up with further design improvements, until all the low-hanging fruit is exhausted. Another important consideration is that two of the main bottlenecks to humans doing faster scientific research are training time and communication bandwidth. If we could train a new mind to be a cutting-edge scientist in ten minutes, and if scientists could near-instantly trade their experience, knowledge, concepts, ideas, and intuitions to their collaborators, then scientific progress might be able to proceed much more rapidly. Those sorts of bottlenecks are exactly the sort of bottleneck that might give automated innovators an enormous edge over human innovators even without large advantages in hardware or algorithms. ↩
10 Specifically, rockets experience a wider range of temperatures and pressures, traverse those ranges more rapidly, and are also packed more fully with explosives. ↩
11 Consider Bird and Layzell's example of a very simple genetic algorithm that was tasked with evolving an oscillating circuit. Bird and Layzell were astonished to find that the algorithm made no use of the capacitor on the chip; instead, it had repurposed the circuit tracks on the motherboard as a radio to replay the oscillating signal from the test device back to the test device.
This was not a very smart program. This is just using hill climbing on a very small solution space. In spite of this, the solution turned out to be outside the space of solutions the programmers were themselves visualizing. In a computer simulation, this algorithm might have behaved as intended, but the actual solution space in the real world was wider than that, allowing hardware-level interventions.
In the case of an intelligent system that's significantly smarter than humans on whatever axes you're measuring, you should by default expect the system to push toward weird and creative solutions like these, and for the chosen solution to be difficult to anticipate. ↩
One way to think about the goal is that we want to "zero in" on valuable futures: it's unclear what exactly a good future looks like, and we can't get an "assurance," but for example a massive Manhattan Project to develop whole brain emulation is a not-implausible path to zeroing in, assuming WBE isn't too difficult to achieve on the relevant timescale and assuming you can avoid accelerating difficult-to-align AI too much in the process. It's a potentially promising option for zeroing in because emulated humans could be leveraged to do a lot of cognitive work in a compressed period of time to sort out key questions in moral psychology+philosophy, neuroscience, computer science, etc. that we need to answer in order to get a better picture of good outcomes.
This is also true for a Manhattan Project to develop a powerful search algorithm that generates smart creative policies to satisfy our values, while excluding hazardous parts of the search space -- this is the AI route.
Trying to ensure that AI is conscious, without also solving WBE or alignment or global coordination or something of that kind in the process, doesn't have this "zeroing in" property. It's more of a gamble that hopefully good-ish futures have a high enough base rate even when we don't put a lot of work into steering in a specific direction, that maybe arbitrary conscious systems would make good things happen. But building a future of conscious AI systems opens up a lot of ways for suffering to end up proliferating in the universe, just as it opens up a lot of ways for happiness to end up proliferating in the universe. Just as it isn't obvious that e.g. rabbits experience more joy than suffering in the natural world, it isn't obvious that conscious AI systems in a multipolar outcome would experience more joy than suffering. (Or otherwise experience good-on-net lives.)
I think if an AI singleton isn't infeasible or prohibitively difficult to achieve, then it's likely to happen eventually regardless of what we'd ideally prefer to have happen, absent some intervention to prevent it. Either it's not achievable, or something needs to occur to prevent anyone in the world from reaching that point. If you're worried about singletons, I don't think pursuing multipolar outcomes and/or conscious-AI outcomes should be a priority for you, because I don't think either of those paths concentrates very much probability mass (if any) into scenarios where singletons start off feasible but something blocks them from occurring.
Multipolar scenarios are likelier to occur in scenarios where singletons simply aren't feasible, as a background fact about the universe; but conditional on singletons being feasible, I'm skeptical that achieving a multipolar AI outcome would do much (if anything) to prevent a singleton from occurring afterward, and I think it would make alignment much more difficult.
Alignment and WBE look like difficult tasks, but they have the "zeroing in" property, and we don't know exactly how difficult they are. Alignment in particular could turn out to be much harder than it looks or much easier, because there's so little understanding of what specifically is required. (Investigating WBE has less value-of-information because we already have some decent WBE roadmaps.)
To clarify: I don't think it will be especially fruitful to try to ensure AIs are conscious, for the reason you mention: multipolar scenarios don't really work that way, what will happen is determined by what's efficient in a competitive world, which doesn't allow much room to make changes now that will actually persist.
And yes, if a singleton is inevitable, then our only hope for a good future is to do our best to align the singleton, so that it uses its uncontested power to do good things rather than just to pursue whatever nonsense goal it will have bee... (read more)