Update December 22: Our donors came together during the fundraiser to get us most of the way to our $750,000 goal. In all, 251 donors contributed $589,248, making this our second-biggest fundraiser to date. Although we fell short of our target by $160,000, we have since made up this shortfall thanks to November/December donors. I'm extremely grateful for this support, and will plan accordingly for more staff growth over the coming year.
As described in our post-fundraiser update, we are still fairly funding-constrained. December/January donations will have an especially large effect on our 2017–2018 hiring plans and strategy, as we try to assess our future prospects. For some external endorsements of MIRI as a good place to give this winter, see recent evaluations by Daniel Dewey, Nick Beckstead, Owen Cotton-Barratt, and Ben Hoskin.
The Machine Intelligence Research Institute is running its annual fundraiser, and we're using the opportunity to explain why we think MIRI's work is useful from an EA perspective. To that end, we'll be answering questions on a new "Ask MIRI Anything" EA Forum thread on Wednesday, October 12th.
MIRI is a nonprofit research group based in Berkeley, California. We do technical research that’s aimed at ensuring that smarter-than-human AI systems have a positive impact on the world. Some big recent developments:
- We have a new paper out, "Logical Induction," introducing a method for assigning reasonable probabilities to conjectures in mathematics and computer science that outpaces deduction. See Shtetl-Optimized and n-Category Café for recent discussion on math blogs.
- We started work on a new research agenda with a stronger focus on machine learning, “Alignment for Advanced Machine Learning Systems.” This agenda will be occupying about half of our time going forward, with the other half focusing on our agent foundations agenda.
- The Open Philanthropy Project awarded MIRI a one-year $500,000 grant to scale up our research program, with a strong chance of renewal next year. This grant is not a full endorsement of MIRI, and in fact Open Phil has outlined a number of points of disagreement with MIRI's current research approach. I discuss some of the points of divergence below.
Our recent technical progress and our new set of research directions put us in a better position in this fundraiser to capitalize on donors' help and scale up our research activities further.
Our fundraiser, running from September 16 to October 31, has a $750,000 "basic" funding target, along with higher growth and stretch targets if we hit target 1. Our current progress:
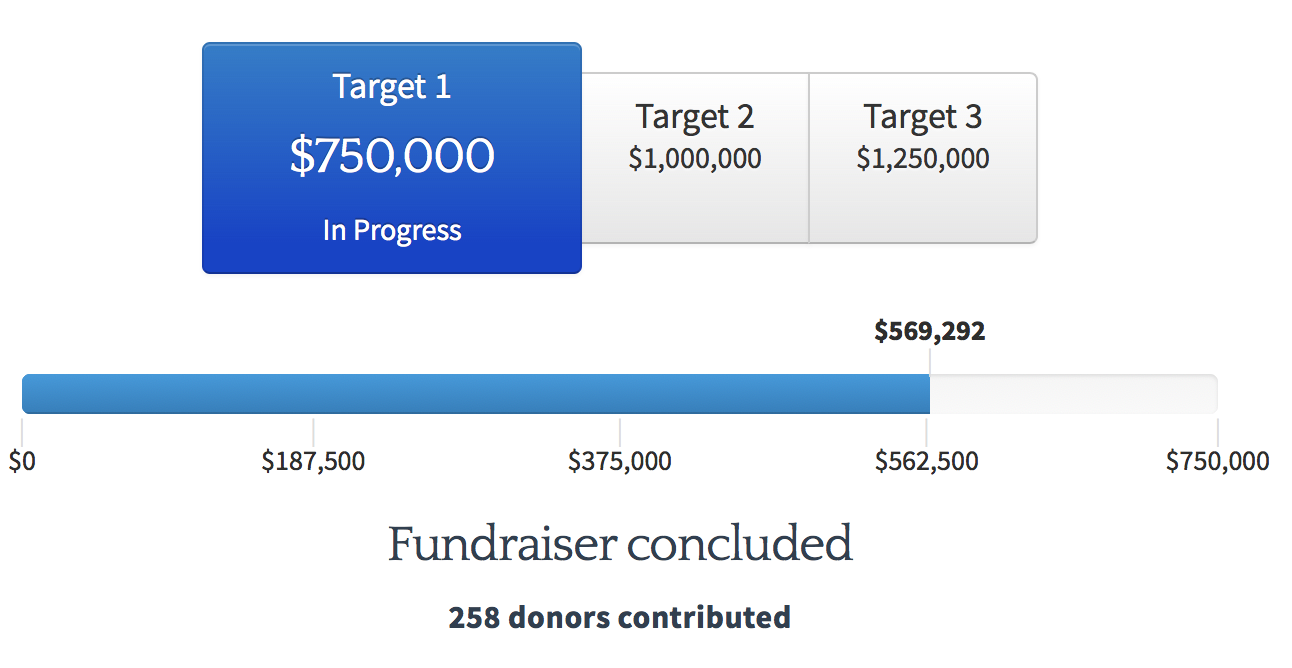
Employer matching and pledges to give later this year also count towards the total. Click here to learn more.
These are ambitious goals. We feel reasonably good about our chance of hitting target 1, but it isn't a sure thing; we'll probably need to see support from new donors in order to hit our target, to offset the fact that a few of our regular donors are giving less than usual this year. To that end, we've written up an introduction to MIRI below, along with updates on what's new at MIRI and what we have planned next:
Why AI? · Why MIRI's approach? · What's new? · Goals for the field · Organizational goals
Why AI?
A number of EA organizations have said that they consider AI to be an important cause area. Here are what I see as the basic reasons for prioritizing research in this area.
Humanity's social and technological dominance stems primarily from our proficiency at reasoning, planning, and doing science (Armstrong). This relatively general problem-solving capacity is roughly what I have in mind when I talk about "intelligence" (Muehlhauser), including artificial intelligence.1
The case for focusing on AI risk mitigation doesn't assume much about how future AI systems will be implemented or used. Here are the claims that I think are key:
1. Whatever problems/tasks/objectives we assign to advanced AI systems probably won't exactly match our real-world objectives. Unless we put in an (enormous, multi-generational) effort to teach AI systems every detail of our collective values (to the extent there is overlap), realistic systems will need to rely on imperfect approximations and proxies for what we want (Soares, Yudkowsky).
2. If the system’s assigned problems/tasks/objectives don’t fully capture our real objectives, it will likely end up with incentives that catastrophically conflict with what we actually want (Bostrom, Russell, Benson-Tilsen & Soares).
3. AI systems can become much more intelligent than humans (Bostrom), to a degree that would likely give AI systems a decisive advantage in arbitrary conflicts (Soares, Branwen).
4. It's hard to predict when smarter-than-human AI will be developed: it could be 15 years away, or 150 years (Open Philanthropy Project). Additionally, progress is likely to accelerate as AI approaches human capability levels, giving us little time to shift research directions once the finish line is in sight (Bensinger).
Stuart Russell's Cambridge talk is an excellent introduction to long-term AI risk.2 Other leading AI researchers who have expressed these kinds of concerns about general AI include Francesca Rossi (IBM), Shane Legg (Google DeepMind), Eric Horvitz (Microsoft), Bart Selman (Cornell), Ilya Sutskever (OpenAI), Andrew Davison (Imperial College London), David McAllester (TTIC), Jürgen Schmidhuber (IDSIA), and Geoffrey Hinton (Google Brain).
Our take-away from this is that we should prioritize early research into aligning future AI systems with our interests, if we can find relevant research problems to study. AI alignment could easily turn out to be many times harder than AI itself, in which case research efforts are currently being wildly misallocated.
Alignment research can involve developing formal and theoretical tools for building and understanding AI systems that are stable and robust ("high reliability"), finding ways to get better approximations of our values in AI systems ("value specification"), and reducing the risks from systems that aren't perfectly reliable or value-specified ("error tolerance").
Why MIRI's approach?
Our recent back-and-forth with the Open Philanthropy Project provides a good jumping-off point for articulating how MIRI's approach differs from other perspectives in AI safety. Open Phil's scientific advisers (along with external reviewers) commented on some of our recent papers here, and I replied here.
One source of disagreement (though certainly not the only one, and not one that everyone at Open Phil considers crucial) is that MIRI is relatively pessimistic about the prospects of aligning advanced AI systems if we don't develop new paradigms that are more theoretically principled than present-day machine learning techniques.
Loosely speaking, we can imagine the space of all smarter-than-human AI systems as an extremely wide and heterogeneous space, in which "alignable AI designs" is a small and narrow target (and "aligned AI designs" smaller and narrower still). I think that the most important thing a marginal alignment researcher can do today is help ensure that the first generally intelligent systems humans design are in the “alignable” region.3 I think that this is unlikely to happen unless researchers have a fairly principled understanding of how the systems they're developing reason, and how that reasoning connects to the intended objectives.
Most of our work is therefore aimed at seeding the field with ideas that may inspire more AI research in the vicinity of (what we expect to be) alignable AI designs. When the first general reasoning machines are developed, we want the developers to be sampling from a space of designs and techniques that are more understandable and reliable than what’s possible in AI today.
Concretely, these three points are often what set apart our research priorities from other candidate approaches:
- We prioritize research that we think could help inspire new AI techniques that are more theoretically principled than current techniques. In practice, this usually involves focusing on the biggest gaps in our current theories, in the hope of developing better and more general theories to undergird subsequent engineering work (Soares).
- We focus more on AI systems' reasoning and planning, rather than on systems' goals, their input and output channels, or features of their environments.4
- We avoid problems we think academic and industry researchers are well-positioned to address (Bensinger).
Unlike the ideas in the previous section, most of the ideas here (especially the second bullet point) haven't been written up yet, and they're only recently seeing much discussion. One of my priorities for the remainder of 2016 is to provide a fuller summary of my and other MIRI researchers' views on these topics.
What's new?
Since my last post to the EA Forum (for our July/August 2015 fundraiser), our main new results with associated write-ups have been:
- "Logical Induction," and a chain of results leading up to it: "Asymptotic Logical Uncertainty and the Benford Test," "Inductive Coherence," and "Asymptotic Convergence in Online Learning with Unbounded Delays."
- "Optimal Predictors," a forthcoming body of work on logical uncertainty by research associate Vadim Kosoy.
- "A Formal Solution to the Grain of Truth Problem," the first reasonably general reduction of ideal game-theoretic reasoning to ideal decision-theoretic reasoning.
- "Quantilizers," a proposed design for "mild optimizers" that satisfice their goals without maximizing.
- "Parametric Bounded Löb’s Theorem and Robust Cooperation of Bounded Agents," a proof that MIRI's previous work on robust and inexploitable game-theoretic cooperation holds for computable systems, by way of new generalizations of Löb's theorem and Gödel’s second incompleteness theorem.
MIRI research fellows and associates co-authored two publications this year in a top AI venue, the 32nd Conference on Uncertainty in Artificial Intelligence: the grain of truth paper, and "Safely Interruptible Agents."
Since August 2015, we've hired two research fellows (Andrew Critch and Scott Garrabrant) and one assistant research fellow (Ryan Carey), and two of our associates (Abram Demski and Mihály Bárász) have signed on to become full-time researchers. We've expanded our associate program, run a seminar series (with a second one ongoing), run seven research workshops (including four during our first Colloquium Series on Robust and Beneficial AI), and sponsored MIRI Summer Fellows and MIRIx programs. We also expanded our operations team and moved into a larger office space.
For more details, see our 2015 in Review and 2016 Strategy Update posts.
Goals for the field
Researchers at MIRI are generally highly uncertain about how the field of AI will develop over the coming years, and there are many different scenarios that strike me as plausible. Conditional on a good outcome, though, I put a fair amount of probability on scenarios that more or less follow the following sketch:
- In the short term, a research community coalesces, develops a good in-principle understanding of what the relevant problems are, and produces formal tools for tackling these problems. AI researchers move toward a minimal consensus about best practices, more open discussions of AI’s long-term social impact, a risk-conscious security mindset (Muehlhauser), and work on error tolerance and value specification.
- In the medium term, researchers build on these foundations and develop a more mature understanding. As we move toward a clearer sense of what smarter-than-human AI systems are likely to look like — something closer to a credible roadmap — we imagine the research community moving toward increased coordination and cooperation in order to discourage race dynamics (Soares).
- In the long term, we would like to see AI-empowered projects used to avert major AI mishaps while humanity works towards the requisite scientific and institutional maturity for making lasting decisions about the far future (Dewey). For this purpose, we’d want to solve a weak version of the alignment problem for limited AI systems — systems just capable enough to serve as useful levers for preventing AI accidents and misuse.
- In the very long term, my hope is that researchers will eventually solve the “full” alignment problem for highly capable, highly autonomous AI systems. Ideally, we want to reach a position where engineers and operators can afford to take their time to dot every i and cross every t before we risk “locking in” any choices that have a large and irreversible effect on the future.
The above is a vague sketch, and we prioritize research we think would be useful in less optimistic scenarios as well. Additionally, “short term” and “long term” here are relative, and different timeline forecasts can have very different policy implications. Still, the sketch may help clarify the directions we’d like to see the research community move in.
Organizational goals
MIRI's current objective is to formalize and solve the problems outlined in our technical agendas. To make this more concrete, one (very ambitious) benchmark I set for us last year was to develop a fully naturalized AIXI by 2020. Logical induction looks like a promising step in that direction, though there are still a number of outstanding questions about how far this formalism (and reflective oracles, optimal predictors, and other frameworks we've developed) can get us towards a general-purpose theory of ideal bounded reasoning.
We currently employ seven technical research staff (six research fellows and one assistant research fellow) and seven research contractors (five associates and two interns).5 Our budget this year is about $1.75M, up from $1.65M in 2015 and $950k in 2014.6 Our eventual goal (subject to revision) is to grow until we have 13–17 technical research staff, at which point our budget would likely be in the $3–4M range. If we reach that point successfully while maintaining a two-year runway, we’re likely to shift out of growth mode.
Our budget estimate for 2017 is roughly $2–2.2M, which means that we’re entering this fundraiser with about 14 months’ runway. We’re uncertain about how many donations we’ll receive between November and next September,7 but projecting from current trends, we expect about 4/5ths of our total donations to come from the fundraiser and 1/5th to come in off-fundraiser.8 Based on this, we have the following fundraiser goals:
Basic target – $750,000. We feel good about our ability to execute our growth plans at this funding level. We’ll be able to move forward comfortably, albeit with somewhat more caution than at the higher targets.
Growth target – $1,000,000. This would amount to about half a year’s runway. At this level, we can afford to make more uncertain but high-expected-value bets in our growth plans. There’s a risk that we’ll dip below a year’s runway in 2017 if we make more hires than expected, but the growing support of our donor base would make us feel comfortable about taking such risks.
Stretch target – $1,250,000. At this level, even if we exceed my growth expectations, we’d be able to grow without real risk of dipping below a year’s runway. Past $1.25M we would not expect additional donations to affect our 2017 plans much, assuming moderate off-fundraiser support.9
If we hit our growth and stretch targets, we’ll be able to execute several additional programs we’re considering with more confidence. These include contracting a larger pool of researchers to do early work with us on logical induction and on our machine learning agenda, and generally spending more time on academic outreach, field-growing, and training or trialing potential collaborators and hires.
As always, you’re invited to get in touch if you have questions about our upcoming plans and recent activities. I’m very much looking forward to seeing what new milestones the growing alignment research community will hit in the coming year, and I’m very grateful for the thoughtful engagement and support that’s helped us get to this point.10
Notes
1 Note that we don't assume that "human-level" artificial intelligence implies artificial consciousness, artificial emotions, or other human-like characteristics. When it comes to artificial intelligence, the only assumption is that if a carbon brain can solve a practical problem, a silicon brain can too (Chalmers). ↩
2 For other good overviews of the problem, see Yudkowsky's So Far: Unfriendly AI Edition and Open Phil's cause report. ↩
3 Ensuring that highly advanced AI systems are in the “alignable” region isn’t necessarily a more important or difficult task than getting from “alignable” to “sufficiently aligned.” However, I expect the wider research community to be better-suited to the latter task. ↩
4 This is partly because of the first bullet point, and partly because we expect reasoning and planning to be a key part of what makes highly capable systems highly capable. To make use of these capabilities (and do so safely), I expect we need a good model of how the system does its cognitive labor, and how this labor ties in to the intended objective.
I haven’t provided any argument for this view here; for people who don’t find it intuitive, I plan to write more on this topic in the near future. ↩
5 This excludes Katja Grace, who heads the AI Impacts project using a separate pool of funds earmarked for strategy/forecasting research. It also excludes me: I contribute to our technical research, but my primary role is administrative. ↩
6 We expect to be slightly under the $1.825M budget we previously projected for 2016, due to taking on fewer new researchers than planned this year. ↩
7 We’re imagining continuing to run one fundraiser per year in future years, possibly in September. ↩
8 Separately, the Open Philanthropy Project is likely to renew our $500,000 grant next year, and we expect to receive the final ($80,000) installment from the Future of Life Institute’s three-year grants.
For comparison, our revenue was about $1.6 million in 2015: $167k in grants, $960k in fundraiser contributions, and $467k in off-fundraiser (non-grant) contributions. Our situation in 2015 was somewhat different, however: we ran two 2015 fundraisers, whereas we’re skipping our winter fundraiser this year and advising December donors to pledge early or give off-fundraiser. ↩
9 At significantly higher funding levels, we’d consider running other useful programs, such as a prize fund. Shoot me an e-mail if you’d like to talk about the details. ↩
10 Thanks to Rob Bensinger for helping draft this post. ↩
We originally sent Nick Beckstead what we considered our four most important 2015 results, at his request; these were (1) the incompatibility of the "Inductive Coherence" framework and the "Asymptotic Convergence in Online Learning with Unbounded Delays" framework; (2) the demonstration in "Proof-Producing Reflection for HOL" that a non-pathological form of self-referential reasoning is possible in a certain class of theorem-provers; (3) the reflective oracles result presented in "A Formal Solution to the Grain of Truth Problem," "Reflective Variants of Solomonoff Induction and AIXI," and "Reflective Oracles"; (4) and Vadim Kosoy's "Optimal Predictors" work. The papers we listed under 1, 2, and 4 then got used in an external review process they probably weren't very well-suited for.
I think this was more or less just an honest miscommunication. I told Nick in advance that I only assigned an 8% probability to external reviewers thinking the “Asymptotic Convergence…” result was "good" on its own (and only a 20% probability for "Inductive Coherence"). My impression of what happened is that Open Phil staff interpreted my pushback as saying that I thought the external reviews wouldn’t carry much Bayesian evidence (but that the internal reviews still would), where what I was trying to communicate was that I thought the papers didn’t carry very much Bayesian evidence about our technical output (and that I thought the internal reviewers would need to speak to us about technical specifics in order to understand why we thought they were important). Thus, we were surprised when their grant decision and write-up put significant weight on the internal reviews of those papers (and they were surprised that we were surprised). This is obviously really unfortunate, and another good sign that I should have committed more time and care to clearly communicating my thinking from the outset.
Regarding picking better papers for external review: We only put out 10 papers directly related to our technical agendas between Jan 2015 and Mar 2016, so the option space is pretty limited, especially given the multiple constraints Open Phil wanted to meet. Optimizing for technical impressiveness and non-obviousness as a stand-alone result, I might have instead gone with Critch's bounded Löb paper and the grain of truth problem paper over the AC/IC results. We did submit the grain of truth problem paper to Open Phil, but they decided not to review it because it didn't meet other criteria they were interested in.
I’m less pessimistic about building collaborations and partnerships, in part because we’re already on pretty good terms with other folks in the community, and in part because I think we have different models of how technical ideas spread. Regardless, I expect that with more and better communication, we can (upon re-evaluation) raise the probability of Open Phil staff that the work we’re doing is important.
More generally, though, I expect this task to get easier over time as we get better at communicating about our research. There's already a body of AI alignment research (and, perhaps, methodology) that requires the equivalent of multiple university courses to understand, but there aren't curricula or textbooks for teaching it. If we can convince a small pool of researchers to care about the research problems we think are important, this will let us bootstrap to the point where we have more resources for communicating information that requires a lot of background and sustained scholarship, as well as more of the institutional signals that this stuff warrants a time investment.
I can maybe make the time expenditure thus far less mysterious if I mention a couple more ways I erred in trying to communicate my model of MIRI's research agenda:
(I plan to blog more about the details of these later.)
I think these are important mistakes that show I hadn't sufficiently clarified several concepts in my own head, or spent enough time understanding Daniel's position. My hope is that I can do a much better job of avoiding these sorts of failures in the next round of discussion, now that I have a better model of where Open Phil’s staff and advisors are coming from and what the review process looks like.
Yeah, though that was before my time. He did an unpaid internship with us in the summer of 2013, and we’ve occasionally contracted him to tutor MIRI staff. Qiaochu's also a lot socially closer to MIRI; he attended three of our early research workshops.
I think that's a reasonable stance to take, and that there are other possible reasonable stances here too. Some of the variables I expect EAs to vary on include “level of starting confidence in MIRI's mathematical intuitions about complicated formal questions” and “general risk tolerance.” A relatively risk-intolerant donor is right to wait until we have clearer demonstrations of success; and a relatively risk-tolerant donor who starts without a very high confidence in MIRI's intuitions about formal systems might be pushed under a donation threshold by learning that an important disagreement has opened up between us and Daniel Dewey (or between us and other people at Open Phil).
Also, thanks for laying out your thinking in so much detail -- I suspect there are other people who had more or less the same reaction to Open Phil's grant write-up but haven't spoken up about it. I'd be happy to talk more about this over email, too, including answering Qs from anyone else who wants more of my thoughts on this.